Building a Pokémon Recomendation Machine

1 Introduction
When I saw the Complete Pokémon Dataset on Kaggle, I just had to download it and have a look! When I was younger, I was a big fan of Pokémon and used to play it regularly and watch the TV show (to this day I can recite much of the original Pokémon Rap). More recently, my daughter has become a fan, and watches the show incessently (although it beats watching Peppa Pig…). So I am going to have a look over these data and see what they can show us about these pocket monsters.
This is a fairly comprehensive analysis of the data, and will include introductions to a number of different data science techniques. I may further develop these into posts of their own in the future, so will only skim over most of them here. I hope that this post shows a fairly complete example of the types of analyses that it is possible to do with data such as these for prediction and recommendation.
2 Download data
The data about each of the Pokémon can be downloaded directly from Kaggle here, and I have also downloaded some images for each of the Pokémon (at least for Generations 1 to 6) from Kaggle here.
The main data are in the form of a compressed comma separated values (CSV) file. After unzipping the file, we are left with a plain text file where every row is a separate entry, and the various columns of the data set are separated by commas. So let’s load the data in using the read.csv function, which will generate a data.frame object, and take a look at it:
pokedat <- read.csv("pokemon.csv")
rownames(pokedat) <- pokedat[["name"]]
dim(pokedat)## [1] 801 41So we have information for 41 variables for 801 unique Pokémon. Each Pokémon has a unique number assigned to it in the so called “Pokédex”, which is common between this data set and the list of Pokémon images. This makes it easy to link the two. Back in my day, there were only 151 Pokémon to keep track of, but many years later they have added more and more with each “Generation”. Pokémon Generation 8 is the most recent and has only recently been released, so we can see which generations are present in this data set by using the table function, which will show us the number of entries with each value:
table(pokedat[["generation"]])##
## 1 2 3 4 5 6 7
## 151 100 135 107 156 72 80So we can see the 151 Generation 1 Pokémon, but also additional Pokémon from up to Generation 7. We can get a fairly broad overview of the data set by using the str function to gain an overview of what is contained within each of the columns of this data.frame:
str(pokedat)## 'data.frame': 801 obs. of 41 variables:
## $ abilities : Factor w/ 482 levels "['Adaptability', 'Download', 'Analytic']",..: 244 244 244 22 22 22 453 453 453 348 ...
## $ against_bug : num 1 1 1 0.5 0.5 0.25 1 1 1 1 ...
## $ against_dark : num 1 1 1 1 1 1 1 1 1 1 ...
## $ against_dragon : num 1 1 1 1 1 1 1 1 1 1 ...
## $ against_electric : num 0.5 0.5 0.5 1 1 2 2 2 2 1 ...
## $ against_fairy : num 0.5 0.5 0.5 0.5 0.5 0.5 1 1 1 1 ...
## $ against_fight : num 0.5 0.5 0.5 1 1 0.5 1 1 1 0.5 ...
## $ against_fire : num 2 2 2 0.5 0.5 0.5 0.5 0.5 0.5 2 ...
## $ against_flying : num 2 2 2 1 1 1 1 1 1 2 ...
## $ against_ghost : num 1 1 1 1 1 1 1 1 1 1 ...
## $ against_grass : num 0.25 0.25 0.25 0.5 0.5 0.25 2 2 2 0.5 ...
## $ against_ground : num 1 1 1 2 2 0 1 1 1 0.5 ...
## $ against_ice : num 2 2 2 0.5 0.5 1 0.5 0.5 0.5 1 ...
## $ against_normal : num 1 1 1 1 1 1 1 1 1 1 ...
## $ against_poison : num 1 1 1 1 1 1 1 1 1 1 ...
## $ against_psychic : num 2 2 2 1 1 1 1 1 1 1 ...
## $ against_rock : num 1 1 1 2 2 4 1 1 1 2 ...
## $ against_steel : num 1 1 1 0.5 0.5 0.5 0.5 0.5 0.5 1 ...
## $ against_water : num 0.5 0.5 0.5 2 2 2 0.5 0.5 0.5 1 ...
## $ attack : int 49 62 100 52 64 104 48 63 103 30 ...
## $ base_egg_steps : int 5120 5120 5120 5120 5120 5120 5120 5120 5120 3840 ...
## $ base_happiness : int 70 70 70 70 70 70 70 70 70 70 ...
## $ base_total : int 318 405 625 309 405 634 314 405 630 195 ...
## $ capture_rate : Factor w/ 34 levels "100","120","125",..: 26 26 26 26 26 26 26 26 26 21 ...
## $ classfication : Factor w/ 588 levels "Abundance Pokémon",..: 449 449 449 299 187 187 531 546 457 585 ...
## $ defense : int 49 63 123 43 58 78 65 80 120 35 ...
## $ experience_growth: int 1059860 1059860 1059860 1059860 1059860 1059860 1059860 1059860 1059860 1000000 ...
## $ height_m : num 0.7 1 2 0.6 1.1 1.7 0.5 1 1.6 0.3 ...
## $ hp : int 45 60 80 39 58 78 44 59 79 45 ...
## $ japanese_name : Factor w/ 801 levels "Abagouraアバゴーラ",..: 200 201 199 288 417 416 794 334 336 80 ...
## $ name : Factor w/ 801 levels "Abomasnow","Abra",..: 73 321 745 95 96 93 656 764 56 88 ...
## $ percentage_male : num 88.1 88.1 88.1 88.1 88.1 88.1 88.1 88.1 88.1 50 ...
## $ pokedex_number : int 1 2 3 4 5 6 7 8 9 10 ...
## $ sp_attack : int 65 80 122 60 80 159 50 65 135 20 ...
## $ sp_defense : int 65 80 120 50 65 115 64 80 115 20 ...
## $ speed : int 45 60 80 65 80 100 43 58 78 45 ...
## $ type1 : Factor w/ 18 levels "bug","dark","dragon",..: 10 10 10 7 7 7 18 18 18 1 ...
## $ type2 : Factor w/ 19 levels "","bug","dark",..: 15 15 15 1 1 9 1 1 1 1 ...
## $ weight_kg : num 6.9 13 100 8.5 19 90.5 9 22.5 85.5 2.9 ...
## $ generation : int 1 1 1 1 1 1 1 1 1 1 ...
## $ is_legendary : int 0 0 0 0 0 0 0 0 0 0 ...So we gave a lot of different information contained in this data set, with the vast majority being represented by numerical values. As well as the name by which we likely know them, we have the original Japanese name, as well as their fighting statistics such as hp (Health Points), speed, attack and defense. We also get their specific abilities, which are given in a listed format within square brackets (e.g. three abilities – ['Adaptability', 'Download', 'Analytic'] – for Abomasnow). There are also various other things that we will explore now in the following sections. So let’s explore these data to see how they look, and to check for any inconsistencies that need to be corrected.
3 Data Cleaning
The first step in any data analysis is to check the consistency of the data to ensure that there are no missing values (and if there are, decide the best thing to do with them), to make sure that the data are consistent and fit within expected bounds, and to generally make sure that these data make sense. These are data that somebody else has generated, so it is best not to assume that they are perfect. If there are any issues, this will propogate to our downstream analyses.
3.1 Missing Data
First of all, let’s take a look to see which of the entries for each of the columns is missing (i.e. is coded as NA):
has_na <- apply(pokedat, MAR = 2, FUN = function(x) which(is.na(x)))
has_na[sapply(has_na, length) > 0]## $height_m
## Rattata Raticate Raichu Sandshrew Sandslash Vulpix Ninetales
## 19 20 26 27 28 37 38
## Diglett Dugtrio Meowth Persian Geodude Graveler Golem
## 50 51 52 53 74 75 76
## Grimer Muk Exeggutor Marowak Hoopa Lycanroc
## 88 89 103 105 720 745
##
## $percentage_male
## Magnemite Magneton Voltorb Electrode Staryu Starmie
## 81 82 100 101 120 121
## Ditto Porygon Articuno Zapdos Moltres Mewtwo
## 132 137 144 145 146 150
## Mew Unown Porygon2 Raikou Entei Suicune
## 151 201 233 243 244 245
## Lugia Ho-Oh Celebi Shedinja Lunatone Solrock
## 249 250 251 292 337 338
## Baltoy Claydol Beldum Metang Metagross Regirock
## 343 344 374 375 376 377
## Regice Registeel Kyogre Groudon Rayquaza Jirachi
## 378 379 382 383 384 385
## Deoxys Bronzor Bronzong Magnezone Porygon-Z Rotom
## 386 436 437 462 474 479
## Uxie Mesprit Azelf Dialga Palkia Regigigas
## 480 481 482 483 484 486
## Giratina Phione Manaphy Darkrai Shaymin Arceus
## 487 489 490 491 492 493
## Victini Klink Klang Klinklang Cryogonal Golett
## 494 599 600 601 615 622
## Golurk Cobalion Terrakion Virizion Reshiram Zekrom
## 623 638 639 640 643 644
## Kyurem Keldeo Meloetta Genesect Carbink Xerneas
## 646 647 648 649 703 716
## Yveltal Zygarde Diancie Hoopa Volcanion Type: Null
## 717 718 719 720 721 772
## Silvally Minior Dhelmise Tapu Koko Tapu Lele Tapu Bulu
## 773 774 781 785 786 787
## Tapu Fini Cosmog Cosmoem Solgaleo Lunala Nihilego
## 788 789 790 791 792 793
## Buzzwole Pheromosa Xurkitree Celesteela Kartana Guzzlord
## 794 795 796 797 798 799
## Necrozma Magearna
## 800 801
##
## $weight_kg
## Rattata Raticate Raichu Sandshrew Sandslash Vulpix Ninetales
## 19 20 26 27 28 37 38
## Diglett Dugtrio Meowth Persian Geodude Graveler Golem
## 50 51 52 53 74 75 76
## Grimer Muk Exeggutor Marowak Hoopa Lycanroc
## 88 89 103 105 720 745In general, this seems to be a fairly complete data set, with only three of the variables showing any NA data. We can see that there are 20 Pokémon with no height nor weight data:
subset(pokedat, is.na(height_m) | is.na(weight_kg))[, c("name", "height_m", "weight_kg")]## name height_m weight_kg
## Rattata Rattata NA NA
## Raticate Raticate NA NA
## Raichu Raichu NA NA
## Sandshrew Sandshrew NA NA
## Sandslash Sandslash NA NA
## Vulpix Vulpix NA NA
## Ninetales Ninetales NA NA
## Diglett Diglett NA NA
## Dugtrio Dugtrio NA NA
## Meowth Meowth NA NA
## Persian Persian NA NA
## Geodude Geodude NA NA
## Graveler Graveler NA NA
## Golem Golem NA NA
## Grimer Grimer NA NA
## Muk Muk NA NA
## Exeggutor Exeggutor NA NA
## Marowak Marowak NA NA
## Hoopa Hoopa NA NA
## Lycanroc Lycanroc NA NAMany of these are Pokémon that I know from Generation 1, and in fact seem to be sets of evolutions. For instance, Rattata evolves into Raticate:


Sandshrew evolves into Sandslash:


And Vulpix evolves into Ninetales:


There are also a couple of other none-Generation 1 Pokémon, including Lycanroc which is one of my daughter’s favourited from Pokémon Sun and Moon:

Lycanroc
However, there is no obvious reason why values are missing. There are methods that can be used to account for missing data. One possible approach is to impute the data – that is, we use the rest of the data to give us a rough idea of what we should see for these missing values. An example of this is to simply use the mean of the non-missing values for the missing variable. However, in this case, we can actually find these missing values by visiting an online Pokedex, so let’s correct these, ensuring that we match the units for weight (kg) and height (m):
missing_height <- list(Rattata = c(height_m = 0.3, weight_kg = 3.5),
Raticate = c(height_m = 0.7, weight_kg = 18.5),
Raichu = c(height_m = 0.8, weight_kg = 30.0),
Sandshrew = c(height_m = 0.6, weight_kg = 12.0),
Sandslash = c(height_m = 1.0, weight_kg = 29.5),
Vulpix = c(height_m = 0.6, weight_kg = 9.9),
Ninetales = c(height_m = 1.1, weight_kg = 19.9),
Diglett = c(height_m = 0.2, weight_kg = 0.8),
Dugtrio = c(height_m = 0.7, weight_kg = 33.3),
Meowth = c(height_m = 0.4, weight_kg = 4.2),
Persian = c(height_m = 1.0, weight_kg = 32.0),
Geodude = c(height_m = 0.4, weight_kg = 20.0),
Graveler = c(height_m = 0.3, weight_kg = 105.0),
Golem = c(height_m = 1.4, weight_kg = 300.0),
Grimer = c(height_m = 0.9, weight_kg = 30.0),
Muk = c(height_m = 1.2, weight_kg = 30.0),
Exeggutor = c(height_m = 2.0, weight_kg = 120.0),
Marowak = c(height_m = 1.0, weight_kg = 45.0),
Hoopa = c(height_m = 0.5, weight_kg = 9.0),
Lycanroc = c(height_m = 0.8, weight_kg = 25.0))
missing_height <- t(rbind.data.frame(missing_height))
pokedat[match(rownames(missing_height), pokedat[["name"]]), c("height_m", "weight_kg")] <- missing_heightThere are also 98 Pokémon with a missing percentage_male value. This value gives the proportion of the Pokémon out in the world that you might come across in the game that are male as a percentage. These seem to be spread throughout the entire list of Pokémon across all Generations, with no clear reason as to why they have missing values:
head(subset(pokedat, is.na(percentage_male)))## abilities against_bug
## Magnemite ['Magnet Pull', 'Sturdy', 'Analytic'] 0.5
## Magneton ['Magnet Pull', 'Sturdy', 'Analytic'] 0.5
## Voltorb ['Soundproof', 'Static', 'Aftermath'] 1.0
## Electrode ['Soundproof', 'Static', 'Aftermath'] 1.0
## Staryu ['Illuminate', 'Natural Cure', 'Analytic'] 1.0
## Starmie ['Illuminate', 'Natural Cure', 'Analytic'] 2.0
## against_dark against_dragon against_electric against_fairy
## Magnemite 1 0.5 0.5 0.5
## Magneton 1 0.5 0.5 0.5
## Voltorb 1 1.0 0.5 1.0
## Electrode 1 1.0 0.5 1.0
## Staryu 1 1.0 2.0 1.0
## Starmie 2 1.0 2.0 1.0
## against_fight against_fire against_flying against_ghost
## Magnemite 2.0 2.0 0.25 1
## Magneton 2.0 2.0 0.25 1
## Voltorb 1.0 1.0 0.50 1
## Electrode 1.0 1.0 0.50 1
## Staryu 1.0 0.5 1.00 1
## Starmie 0.5 0.5 1.00 2
## against_grass against_ground against_ice against_normal
## Magnemite 0.5 4 0.5 0.5
## Magneton 0.5 4 0.5 0.5
## Voltorb 1.0 2 1.0 1.0
## Electrode 1.0 2 1.0 1.0
## Staryu 2.0 1 0.5 1.0
## Starmie 2.0 1 0.5 1.0
## against_poison against_psychic against_rock against_steel
## Magnemite 0 0.5 0.5 0.25
## Magneton 0 0.5 0.5 0.25
## Voltorb 1 1.0 1.0 0.50
## Electrode 1 1.0 1.0 0.50
## Staryu 1 1.0 1.0 0.50
## Starmie 1 0.5 1.0 0.50
## against_water attack base_egg_steps base_happiness base_total
## Magnemite 1.0 35 5120 70 325
## Magneton 1.0 60 5120 70 465
## Voltorb 1.0 30 5120 70 330
## Electrode 1.0 50 5120 70 490
## Staryu 0.5 45 5120 70 340
## Starmie 0.5 75 5120 70 520
## capture_rate classfication defense experience_growth
## Magnemite 190 Magnet Pokémon 70 1000000
## Magneton 60 Magnet Pokémon 95 1000000
## Voltorb 190 Ball Pokémon 50 1000000
## Electrode 60 Ball Pokémon 70 1000000
## Staryu 225 Starshape Pokémon 55 1250000
## Starmie 60 Mysterious Pokémon 85 1250000
## height_m hp japanese_name name percentage_male
## Magnemite 0.3 25 Coilコイル Magnemite NA
## Magneton 1.0 50 Rarecoilレアコイル Magneton NA
## Voltorb 0.5 40 Biriridamaビリリダマ Voltorb NA
## Electrode 1.2 60 Marumineマルマイン Electrode NA
## Staryu 0.8 30 Hitodemanヒトデマン Staryu NA
## Starmie 1.1 60 Starmieスターミー Starmie NA
## pokedex_number sp_attack sp_defense speed type1 type2
## Magnemite 81 95 55 45 electric steel
## Magneton 82 120 70 70 electric steel
## Voltorb 100 55 55 100 electric
## Electrode 101 80 80 150 electric
## Staryu 120 70 55 85 water
## Starmie 121 100 85 115 water psychic
## weight_kg generation is_legendary
## Magnemite 6.0 1 0
## Magneton 60.0 1 0
## Voltorb 10.4 1 0
## Electrode 66.6 1 0
## Staryu 34.5 1 0
## Starmie 80.0 1 0However, by looking at a few of these in the Pokedex, it would appear that these are generally genderless Pokémon, which would explain the missing values. A sensible value to use in these cases would therefore be 0.5, representing an equal spit of male and female:
pokedat[is.na(pokedat[["percentage_male"]]), "percentage_male"] <- 0.5It is also worth noting that there are also missing values for the type2 Pokémon. These were not picked up as NA values, because they are encoded as a blank entry "“. We can convert this to a more descriptive factor such as”none":
levels(pokedat[["type2"]])[levels(pokedat[["type2"]]) == "none"] <- "none"3.2 Numeric Range
The vast majority of these variables are numeric in nature, so it is worth checking the range of these values to ensure that they are within typical ranges that we might expect. For instance, we would not expect negative values, zero values, or values greater than some sensible limit for things like height, weight, etc. So let’s take an overall look at these data ranges by using the summary() function:
summary(pokedat)## abilities against_bug
## ['Levitate'] : 29 Min. :0.2500
## ['Beast Boost'] : 7 1st Qu.:0.5000
## ['Shed Skin'] : 5 Median :1.0000
## ['Clear Body', 'Light Metal'] : 4 Mean :0.9963
## ['Justified'] : 4 3rd Qu.:1.0000
## ['Keen Eye', 'Tangled Feet', 'Big Pecks']: 4 Max. :4.0000
## (Other) :748
## against_dark against_dragon against_electric against_fairy
## Min. :0.250 Min. :0.0000 Min. :0.000 Min. :0.250
## 1st Qu.:1.000 1st Qu.:1.0000 1st Qu.:0.500 1st Qu.:1.000
## Median :1.000 Median :1.0000 Median :1.000 Median :1.000
## Mean :1.057 Mean :0.9688 Mean :1.074 Mean :1.069
## 3rd Qu.:1.000 3rd Qu.:1.0000 3rd Qu.:1.000 3rd Qu.:1.000
## Max. :4.000 Max. :2.0000 Max. :4.000 Max. :4.000
##
## against_fight against_fire against_flying against_ghost
## Min. :0.000 Min. :0.250 Min. :0.250 Min. :0.000
## 1st Qu.:0.500 1st Qu.:0.500 1st Qu.:1.000 1st Qu.:1.000
## Median :1.000 Median :1.000 Median :1.000 Median :1.000
## Mean :1.066 Mean :1.135 Mean :1.193 Mean :0.985
## 3rd Qu.:1.000 3rd Qu.:2.000 3rd Qu.:1.000 3rd Qu.:1.000
## Max. :4.000 Max. :4.000 Max. :4.000 Max. :4.000
##
## against_grass against_ground against_ice against_normal
## Min. :0.250 Min. :0.000 Min. :0.250 Min. :0.000
## 1st Qu.:0.500 1st Qu.:1.000 1st Qu.:0.500 1st Qu.:1.000
## Median :1.000 Median :1.000 Median :1.000 Median :1.000
## Mean :1.034 Mean :1.098 Mean :1.208 Mean :0.887
## 3rd Qu.:1.000 3rd Qu.:1.000 3rd Qu.:2.000 3rd Qu.:1.000
## Max. :4.000 Max. :4.000 Max. :4.000 Max. :1.000
##
## against_poison against_psychic against_rock against_steel
## Min. :0.0000 Min. :0.000 Min. :0.25 Min. :0.2500
## 1st Qu.:0.5000 1st Qu.:1.000 1st Qu.:1.00 1st Qu.:0.5000
## Median :1.0000 Median :1.000 Median :1.00 Median :1.0000
## Mean :0.9753 Mean :1.005 Mean :1.25 Mean :0.9835
## 3rd Qu.:1.0000 3rd Qu.:1.000 3rd Qu.:2.00 3rd Qu.:1.0000
## Max. :4.0000 Max. :4.000 Max. :4.00 Max. :4.0000
##
## against_water attack base_egg_steps base_happiness
## Min. :0.250 Min. : 5.00 Min. : 1280 Min. : 0.00
## 1st Qu.:0.500 1st Qu.: 55.00 1st Qu.: 5120 1st Qu.: 70.00
## Median :1.000 Median : 75.00 Median : 5120 Median : 70.00
## Mean :1.058 Mean : 77.86 Mean : 7191 Mean : 65.36
## 3rd Qu.:1.000 3rd Qu.:100.00 3rd Qu.: 6400 3rd Qu.: 70.00
## Max. :4.000 Max. :185.00 Max. :30720 Max. :140.00
##
## base_total capture_rate classfication defense
## Min. :180.0 45 :250 Dragon Pokémon : 8 Min. : 5.00
## 1st Qu.:320.0 190 : 75 Mouse Pokémon : 6 1st Qu.: 50.00
## Median :435.0 255 : 69 Mushroom Pokémon: 6 Median : 70.00
## Mean :428.4 75 : 61 Balloon Pokémon : 5 Mean : 73.01
## 3rd Qu.:505.0 3 : 58 Fairy Pokémon : 5 3rd Qu.: 90.00
## Max. :780.0 120 : 55 Flame Pokémon : 5 Max. :230.00
## (Other):233 (Other) :766
## experience_growth height_m hp
## Min. : 600000 Min. : 0.100 Min. : 1.00
## 1st Qu.:1000000 1st Qu.: 0.600 1st Qu.: 50.00
## Median :1000000 Median : 1.000 Median : 65.00
## Mean :1054996 Mean : 1.155 Mean : 68.96
## 3rd Qu.:1059860 3rd Qu.: 1.500 3rd Qu.: 80.00
## Max. :1640000 Max. :14.500 Max. :255.00
##
## japanese_name name percentage_male
## Abagouraアバゴーラ : 1 Abomasnow : 1 Min. : 0.00
## Absolアブソル : 1 Abra : 1 1st Qu.: 50.00
## Abulyアブリー : 1 Absol : 1 Median : 50.00
## Aburibbonアブリボン: 1 Accelgor : 1 Mean : 48.47
## Achamoアチャモ : 1 Aegislash : 1 3rd Qu.: 50.00
## Agehuntアゲハント : 1 Aerodactyl: 1 Max. :100.00
## (Other) :795 (Other) :795
## pokedex_number sp_attack sp_defense speed
## Min. : 1 Min. : 10.00 Min. : 20.00 Min. : 5.00
## 1st Qu.:201 1st Qu.: 45.00 1st Qu.: 50.00 1st Qu.: 45.00
## Median :401 Median : 65.00 Median : 66.00 Median : 65.00
## Mean :401 Mean : 71.31 Mean : 70.91 Mean : 66.33
## 3rd Qu.:601 3rd Qu.: 91.00 3rd Qu.: 90.00 3rd Qu.: 85.00
## Max. :801 Max. :194.00 Max. :230.00 Max. :180.00
##
## type1 type2 weight_kg generation
## water :114 :384 Min. : 0.10 Min. :1.00
## normal :105 flying : 95 1st Qu.: 9.00 1st Qu.:2.00
## grass : 78 ground : 34 Median : 27.30 Median :4.00
## bug : 72 poison : 34 Mean : 60.94 Mean :3.69
## psychic: 53 fairy : 29 3rd Qu.: 63.00 3rd Qu.:5.00
## fire : 52 psychic: 29 Max. :999.90 Max. :7.00
## (Other):327 (Other):196
## is_legendary
## Min. :0.00000
## 1st Qu.:0.00000
## Median :0.00000
## Mean :0.08739
## 3rd Qu.:0.00000
## Max. :1.00000
## We can learn a few things from this. For instance, if we look at the character type variables, “Levitate” is the most common ability (although note that this is only counting the cases where there is only a single ability – more on this later), “Dragon Pokémon” are the most common classfication [sic] (although the majority of the Pokémon are given a unique classification, which seems to go against the idea of classification), and “water” and “normal” type Pokémon are very common, and many Pokémon have flying as their secondary type. If we look at the numeric type variables, we can see that the against_ values appear to be numeric values between 0 and 4 in multiples of 0.25 (they represent the Pokémon’s strength against particular Pokémon types during battle), attack, defense and speed vary between 5 and 185, 230 and 180 respectively (so there is quite a big range depending on which Pokémon you have in a fight), there is at least one Pokémon that starts with a base happiness score of 0 (in fact there are 36, which is quite sad!), the percentage of males varies between 0 and 100 with 98 missing values (as expected). But overall there do not appear to be any strange outliers in these data. There are some pretty big Pokémon, but we will explore this in a little more detail later.
3.3 Change Variable Class
The m ajority of these data have been classified correctly by the read.data() function as either numeric or characters (which are factorised automaticallyfor use in model and potting functions later). However, there are some changes that we may wish to make. Firstly, the generation and is_legendary variables should not be considered numeric, even though they are represented by numbers. For instance, a Pokémon could not come from Generation 2.345. So let’s make these changes from numeric to factorised character variables. Note that there is a natural order to the generation values, so I will ensure that these are factorised as ordinal, just in case this comes into play later:
pokedat[["generation"]] <- factor(as.character(pokedat[["generation"]]), order = TRUE)
pokedat[["is_legendary"]] <- factor(as.character(pokedat[["is_legendary"]]))These variabbles have been classified as factors even though they are represented by numeric values. The values representing the factor levels can actually be anything we choose, so it may be useful to change these to something more descriptive. For instance, it may be worth adding the word “Generation” to the generation variable, whilst the is_legendary variable may be more useful as a binary TRUE/FALSE value. It doesn’t matter what we put, since for later analyses dummy numeric variables will be used for calculations:
levels(pokedat[["generation"]]) <- paste("Generation", levels(pokedat[["generation"]]))
levels(pokedat[["is_legendary"]]) <- c(FALSE, TRUE)The defaults for the other factors seem to be suitable, so I will leave thse as they are.
In comparison, the capture_rate value is being classed as a factor, even though it should be a number. Why is this?
levels(pokedat[["capture_rate"]])## [1] "100" "120"
## [3] "125" "127"
## [5] "130" "140"
## [7] "145" "15"
## [9] "150" "155"
## [11] "160" "170"
## [13] "180" "190"
## [15] "200" "205"
## [17] "220" "225"
## [19] "235" "25"
## [21] "255" "3"
## [23] "30" "30 (Meteorite)255 (Core)"
## [25] "35" "45"
## [27] "50" "55"
## [29] "60" "65"
## [31] "70" "75"
## [33] "80" "90"Aha. So there is a non-numeric value in there – 30 (Meteorite)255 (Core). Let’s see which Pokémon this applies to:
as.character(subset(pokedat, capture_rate == "30 (Meteorite)255 (Core)")[["name"]])## [1] "Minior"This is a “Meteor” type Pokémon that appears to have a different capture rate under different conditions. Baased on the online Pokedex, the canonical value to use here is 30 for its Meteorite form, so let’s use this and convert it into a numeric value. One thing to bear in mind here is that factors can be a little funny. When I convert to a number, it will convert the level values to a number, not necessarily the values themselves. So in this case, it will not give me the values but instead will give me the order of the values. For instance. look at the output of the following example:
t <- factor(c("1", "2", "3", "20"))
data.frame(factor = t, level = levels(t), number = as.numeric(t))## factor level number
## 1 1 1 1
## 2 2 2 2
## 3 3 20 4
## 4 20 3 3So the levels are based on a character sort rather than a numeric sort, which puts “20” ahead of “4”. Then, to add to this further, the factor “20” is actually the 3rd factor so gets the value 3, whilst the factor “3” is the 4th level, and so gets a value 4. So the output is definitely not what we would expect when converting this to a number. To avoid this, we need to convert to a character value before we do anything else:
pokedat[["capture_rate"]] <- as.character(pokedat[["capture_rate"]])
pokedat[pokedat[["name"]] == "Minior", "capture_rate"] = "30"
pokedat[["capture_rate"]] <- as.numeric(pokedat[["capture_rate"]])This should now be a pretty clean data set ready for analysis.
4 Exploratory Analyses
There are a lot of data here, and I could spend ages exploring every facet, but I just really wanrt to get a tester for these data here. First of all, let’s take a look at the distribution of some of the main statistics to see how they look across the dataset. For the majority of these plots, I will be using the ggplot2 library which offers a very nice way to produce publication-quality figures using a standardised lexicon, along with the dplyr package which provides a simple way to rearrange data into suitable formats for producing plots. These are part of the Tidyverse suite of packages from Hadley Wickham, and form a very useful suite of packages with a common grammar that can be used together to make Data Science more efficient and to produce beautiful plots easily. Handy cheat sheets can be found for dplyr and ggplot2:
library("ggplot2")
library("dplyr")
library("ggrepel")
library("RColorBrewer")4.1 Attack
First of all, let’s take a look at the attack strength of all Pokémon split by their main type:
pokedat %>% mutate('MainType' = type1) %>%
ggplot(aes(x = attack, fill = MainType)) +
geom_density(alpha = 0.2) +
xlab("Attack Strength") + ylab("Density") +
theme_bw() +
theme(axis.title = element_text(size = 24, face = "bold"),
axis.text = element_text(size = 18),
legend.title = element_text(size = 24, face = "bold"),
legend.text = element_text(size = 20))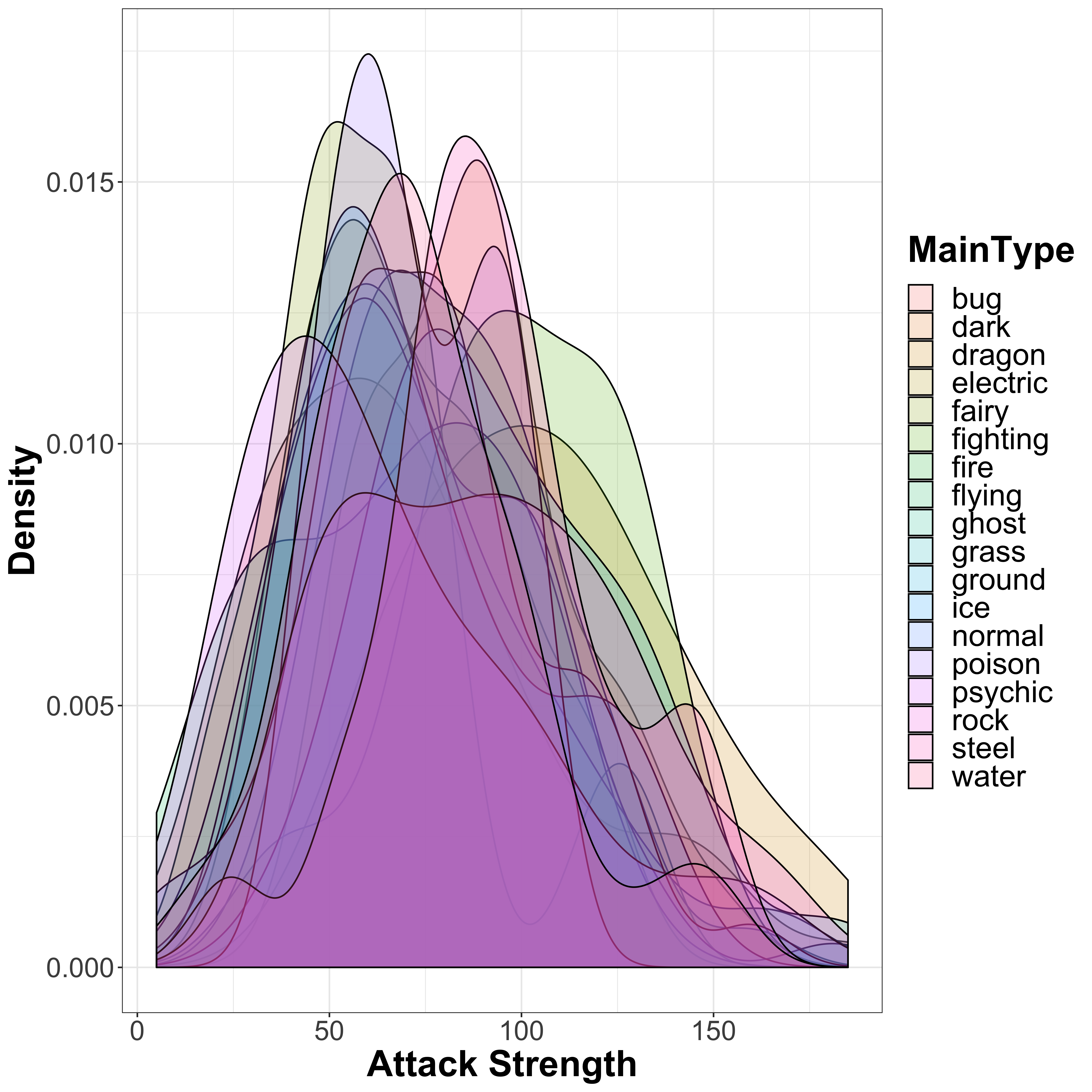
In general, there is a wide range of attack strengths and they are largely distributed with a roughly normal distribution around the mean attack strength of 77.86 that we saw earlier. However, we do see that there are some differences in the different Pokémon types available. However, this probably isn’t the easiest way to see differences between the groups. Instead, let’s use a boxplot. Here, we can see the overall distribution, with the 25th percentile, the median (50th percentile), and the 75th percentile making up the range of the box, and outliers (I believe those with values in the bottom 2.5th percentile or upper 97.5th percentile) highlighted as points on the plot. I have added notches to the boxplots, which show the confidence interval represeneted by:
\[median \pm \frac{1.58*IQR}{\sqrt{n}}\] Where IQR is the interquartile range. Essentially, if the notch values do not overlap between two boxes, it suggests that there may be a statistically significant difference between them:
pokedat %>% mutate('MainType' = type1) %>%
ggplot(aes(y = attack, x = MainType, fill = MainType)) +
geom_boxplot(notch = TRUE) +
xlab("Attack Strength") + ylab("Density") +
theme_bw() +
theme(axis.title = element_text(size = 24, face = "bold"),
axis.text.x = element_text(size = 18, angle = 90, hjust = 1),
axis.text.y = element_text(size = 18),
legend.title = element_text(size = 24, face = "bold"),
legend.text = element_text(size = 20))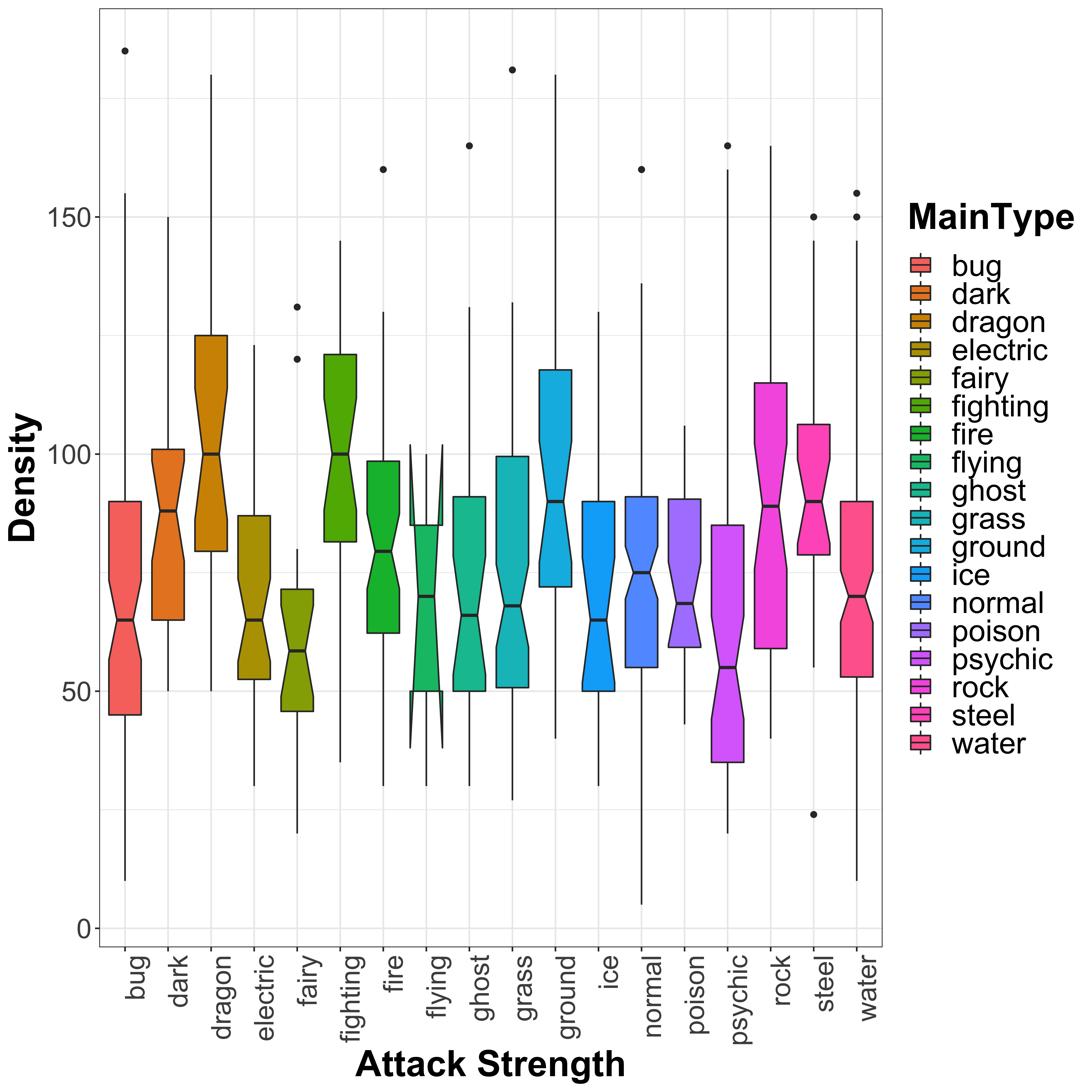
From this plot, we can see that ‘dragon’, ‘fighting’, ‘ground’, ‘rock’ and ‘steel’ type Pokémon have higher attack strength, whilst ‘fairy’ and ‘psychic’ type seem to have slightly lower attack strength. This would make sense based on the names, and we can test this a little more formally by using an ANOVA (analysis of variance) analysis to look for significant effects of the Pokémon type on the attack strength. This can be done quite simply by using linear models:
attack_vs_type1 <- lm(attack ~ type1, data = pokedat)
summary(attack_vs_type1)##
## Call:
## lm(formula = attack ~ type1, data = pokedat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -70.16 -22.31 -3.50 19.26 114.88
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 70.1250 3.6263 19.338 < 0.0000000000000002 ***
## type1dark 17.6681 6.7675 2.611 0.009208 **
## type1dragon 36.2824 6.9439 5.225 0.000000223 ***
## type1electric 0.6955 6.1178 0.114 0.909515
## type1fairy -8.0139 8.1087 -0.988 0.323308
## type1fighting 29.0536 6.8531 4.239 0.000025078 ***
## type1fire 11.3750 5.5998 2.031 0.042561 *
## type1flying -3.4583 18.1316 -0.191 0.848783
## type1ghost 2.6157 6.9439 0.377 0.706501
## type1grass 3.6442 5.0288 0.725 0.468871
## type1ground 24.6875 6.5375 3.776 0.000171 ***
## type1ice 3.1793 7.3700 0.431 0.666301
## type1normal 5.0369 4.7082 1.070 0.285036
## type1poison 2.5313 6.5375 0.387 0.698719
## type1psychic -4.5590 5.5691 -0.819 0.413253
## type1rock 20.5417 5.8473 3.513 0.000468 ***
## type1steel 22.9583 7.2527 3.166 0.001608 **
## type1water 3.1820 4.6320 0.687 0.492311
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 30.77 on 783 degrees of freedom
## Multiple R-squared: 0.1039, Adjusted R-squared: 0.08448
## F-statistic: 5.343 on 17 and 783 DF, p-value: 0.00000000002374It is not a great model by any means, as the R-squared values suggest that Pokémon type alone explains only a small proportion of the variance in the data. From the summary of the model, we can see that the fit model has an intercept of 70.1 (which is close to the overall mean of 77.86), with an offset specific to each of the different types. As we saw from the boxplot, ‘dragon’, ‘fighting’, ‘ground’, ‘rock’ and ‘steel’ all have significant increases in attack (as can be seen by the resulting p-value), but also ‘dark’ and ‘fire’ type which I missed from looking at the boxplot. We see also that ‘fairy’ and ‘psychic’ type Pokémon show a decrease in attack strength, however this difference is not significant. So if you want a strong Pokémon, then these types are your best shot:
- dark
- dragon
- fighting
- fire
- ground
- rock
- steel
It is also worth mentioning that there are a few outliers here, which represent ridiculously powerful Pokémon. In general, these are those with a strength greater than 150, but there are also two fairy Pokémon with higher strength than is typically seen within the ‘fairy’ type Pokémon. Let’s use the Cook’s Distance to identify the outliers from the above model. The idea here is to test the influence of each Pokémon by comparing the least-squares regression with and without the sample included. A higher value indicates a possible outlier. So let’s have a look at the outliers, which we are going to class as those with a Cook’s Distance greater than 4 times the mean of the Cook’s Distance over the entire data set (note that this is a commonly used threshold, but is entirely arbitrary):
library("ggrepel")
library("RColorBrewer")
cookdist <- cooks.distance(attack_vs_type1)
cookdist_lim <- 4*mean(cookdist, na.rm=T)#0.012
data.frame(Pokenum = pokedat[["pokedex_number"]],
Pokename = pokedat[["name"]],
CooksDist = cookdist,
Pokelab = ifelse(cookdist > cookdist_lim, as.character(pokedat[["name"]]), ""),
Outlier = ifelse(cookdist > cookdist_lim, TRUE, FALSE),
PokeCol = ifelse(cookdist > cookdist_lim, as.character(pokedat[["type1"]]), "")) %>%
ggplot(aes(x = Pokenum, y = CooksDist, color = PokeCol, shape = Outlier, size = Outlier, label = Pokelab)) +
geom_point() +
scale_shape_manual(values = c(16, 8)) +
scale_size_manual(values = c(2, 5)) +
scale_color_manual(values = c("black", colorRampPalette(brewer.pal(9, "Set1"))(length(table(pokedat[["type1"]]))))) +
geom_text_repel(nudge_x = 0.2, size = 8) +
geom_hline(yintercept = cookdist_lim, linetype = "dashed", color = "red") +
xlab("Pokedex Number") + ylab("Cook's Distance") +
theme_bw() +
theme(#legend.position = "name",
axis.title = element_text(size = 24, face = "bold"),
axis.text = element_text(size = 18),
legend.title = element_text(size = 24, face = "bold"),
legend.text = element_text(size = 20),
)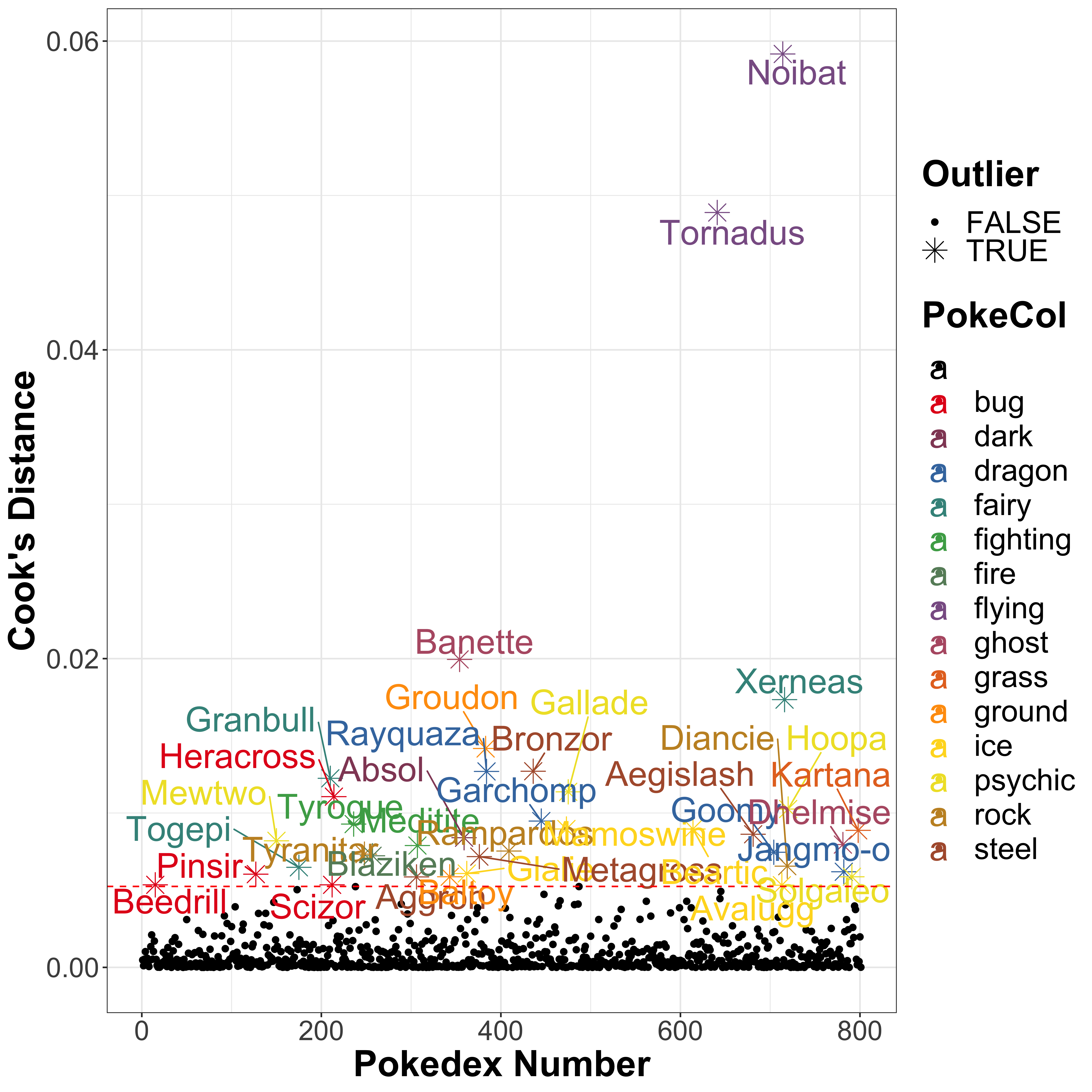
The flying Pokémon Tornadus and Noibat are the biggest outliers. However, interestingly whilst Tornadus has a particularly high attack strength of 100 for a flying type Pokémon, Noibat has a low attack strength of 30. So both are outliers compared to the flyiong type Pokémon as a whole, with a mean of 66.6666667 ± 35.1188458. It is worth mentioning that Tornadus is a Legendary Pokémon which probably explains why it has a higher attack strength.

Tornadus
Whilst these two do not show up on the barplots, it is likely that these are responsible for the strange distribution of the notched boxplot. I suspect this odd shape is a result of the calculation of the confidence interval for the notches exceeding the 25th and 75th percentiles due to a wide range of values, but I do enjoy the fact that it looks like it is itself flying!
The two outlying fairy type Pokémon are Xerneas and Togepi, another favourite of my daughter’s:

Togepi
4.2 Defence
Let’s repeat this to look at the defence values across the different Pokémon types:
pokedat %>% mutate('MainType' = type1) %>%
ggplot(aes(x = defense, fill = MainType)) +
geom_density(alpha = 0.2) +
xlab("Defence Strength") + ylab("Density") +
theme_bw() +
theme(axis.title = element_text(size = 24, face = "bold"),
axis.text = element_text(size = 18),
legend.title = element_text(size = 24, face = "bold"),
legend.text = element_text(size = 20))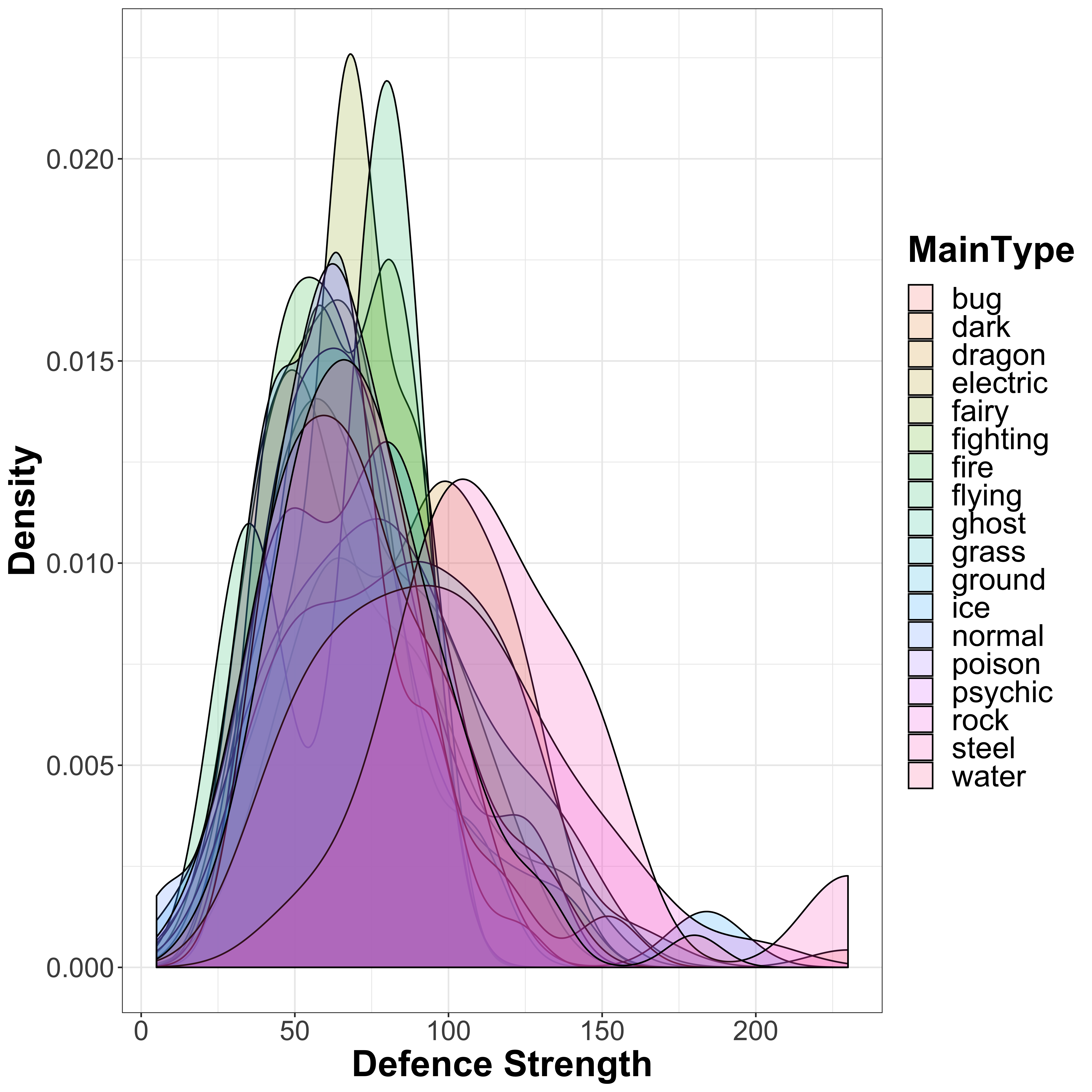
There seems to be a bit more of a distinction between the different types as compared to the attack distribution, so let’s also look at the boxplots:
pokedat %>% mutate('MainType' = type1) %>%
ggplot(aes(y = defense, x = MainType, fill = MainType)) +
geom_boxplot(notch = TRUE) +
xlab("Defence Strength") + ylab("Density") +
theme_bw() +
theme(axis.title = element_text(size = 24, face = "bold"),
axis.text.x = element_text(size = 18, angle = 90, hjust = 1),
axis.text.y = element_text(size = 18),
legend.title = element_text(size = 24, face = "bold"),
legend.text = element_text(size = 20))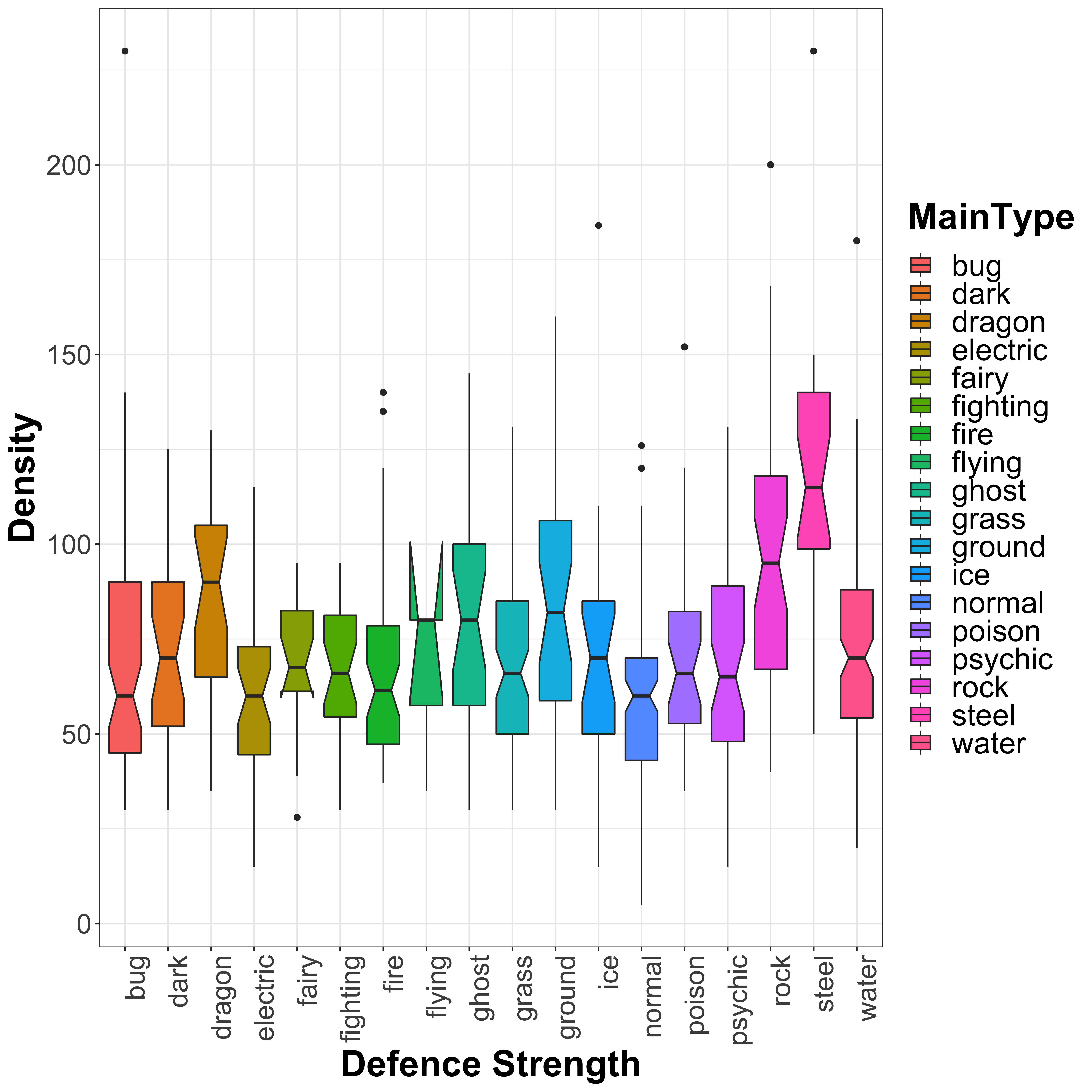
We see more outliers here as compared to the attack strength and a very clear increase in defence for steel and rock type Pokémon (unsurprisingly), as well as dragon type. There are no clear types with lower defence, similar again to what we saw in the attack strength distribution plots. Let’s once again look at this using linear models:
defence_vs_type1 <- lm(defense ~ type1, data = pokedat)
summary(defence_vs_type1)##
## Call:
## lm(formula = defense ~ type1, data = pokedat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -70.208 -20.847 -3.031 16.518 159.153
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 70.84722 3.37247 21.008 < 0.0000000000000002 ***
## type1dark -0.32998 6.29376 -0.052 0.9582
## type1dragon 15.41204 6.45779 2.387 0.0172 *
## type1electric -9.02671 5.68954 -1.587 0.1130
## type1fairy -2.68056 7.54108 -0.355 0.7223
## type1fighting -4.45437 6.37337 -0.699 0.4848
## type1fire -3.05876 5.20784 -0.587 0.5571
## type1flying -5.84722 16.86236 -0.347 0.7289
## type1ghost 8.67130 6.45779 1.343 0.1797
## type1grass 0.02457 4.67678 0.005 0.9958
## type1ground 13.05903 6.07981 2.148 0.0320 *
## type1ice 1.06582 6.85403 0.156 0.8765
## type1normal -11.15198 4.37865 -2.547 0.0111 *
## type1poison -0.81597 6.07981 -0.134 0.8933
## type1psychic -1.58307 5.17923 -0.306 0.7599
## type1rock 25.41944 5.43795 4.674 0.000003469793310 ***
## type1steel 49.36111 6.74494 7.318 0.000000000000623 ***
## type1water 2.63523 4.30777 0.612 0.5409
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 28.62 on 783 degrees of freedom
## Multiple R-squared: 0.1534, Adjusted R-squared: 0.135
## F-statistic: 8.347 on 17 and 783 DF, p-value: < 0.00000000000000022As expected, we see very clear significant increase in defence strength for rock and steel type Pokémon, with a slight increase seen also for dragon and ground type Pokémon. There is also a slight reduction for normal type Pokémon. Flying Pokémon again show an odd distribution, so I expect again to see outliers for this class. Let’s look at the outliers now, again using the COok’s Distance:
cookdist <- cooks.distance(defence_vs_type1)
cookdist_lim <- 4*mean(cookdist, na.rm=T)#0.012
data.frame(Pokenum = pokedat[["pokedex_number"]],
Pokename = pokedat[["name"]],
CooksDist = cookdist,
Pokelab = ifelse(cookdist > cookdist_lim, as.character(pokedat[["name"]]), ""),
Outlier = ifelse(cookdist > cookdist_lim, TRUE, FALSE),
PokeCol = ifelse(cookdist > cookdist_lim, as.character(pokedat[["type1"]]), "")) %>%
ggplot(aes(x = Pokenum, y = CooksDist, color = PokeCol, shape = Outlier, size = Outlier, label = Pokelab)) +
geom_point() +
scale_shape_manual(values = c(16, 8)) +
scale_size_manual(values = c(2, 5)) +
scale_color_manual(values = c("black", colorRampPalette(brewer.pal(9, "Set1"))(length(table(pokedat[["type1"]]))))) +
geom_text_repel(nudge_x = 0.2, size = 8) +
geom_hline(yintercept = cookdist_lim, linetype = "dashed", color = "red") +
xlab("Pokedex Number") + ylab("Cook's Distance") +
theme_bw() +
theme(axis.title = element_text(size = 24, face = "bold"),
axis.text = element_text(size = 18),
legend.title = element_text(size = 24, face = "bold"),
legend.text = element_text(size = 20),
)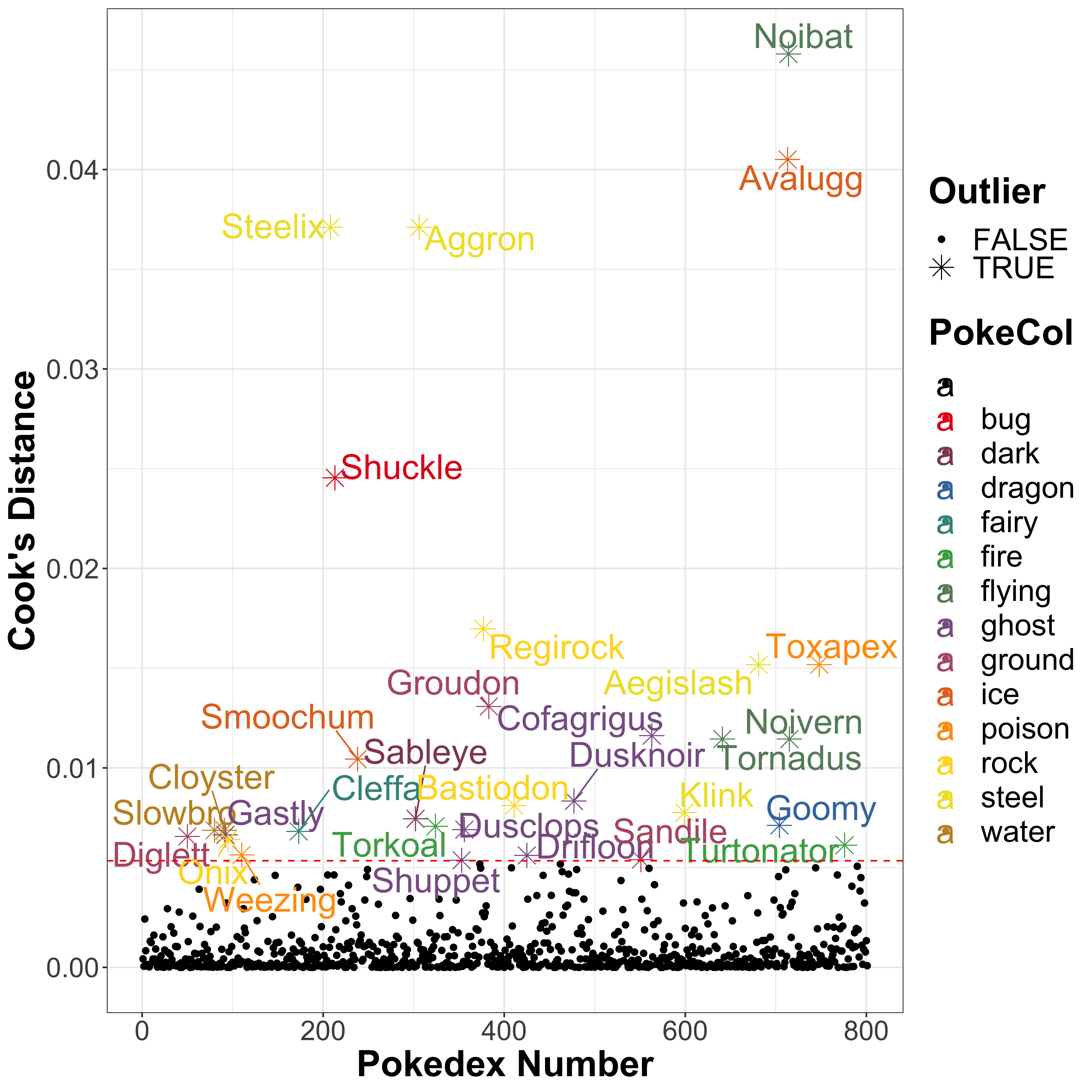
As expected, Noibat and Tornadus are outliers here, and are joined by Noivern (which is an evolution of Noibat). As it turns out, these are the only 3 Pokémon in the flying type, which explains why they show up as outliers and why the boxplot has such a strange distribution. Other outliers include ice-type Pokémon Avalugg (defence 184), steel-type Pokémon Steelix and Aggron (both with defence 230), and bug-type Pokémon Shuckle (defence 230) which doubles up as a rock type Pokémon:

Shuckle
As seen with Shuckle, we should bear in mind that we have only focussed on the primary Pokémon type here, and have not considered the type2 values. So it is possible that we are missing the full picture when looking only at the first class for some of these Pokémon.
4.3 Other
We could do this for all of the different values, and there are many different ways that we may want to examine these data. We can look at eaxch variable in the data set and examine them for odd distributions, we can look for outliers (as we have done above), we can start to examine relationships between variables, and we can look for correlation between different values (which we will do further below). Indeed a considerable amount of time should be spent exploring data in this way to ensure it is of good quality – the old saying “garbage in, garbage out” is very true. But to be honest there are more interesting things that I want to do with these data, so let’s crack on…
4.4 Ensuring we use accurate data classes throughout
It is important to ensure that we are using the data in the correct way for our analyses. First of all let’s take a look at the abilities that each Pokémon has. As it stands, the abilities variable is not terribly useful, as it fails to link Pokémon who may share abilities but not exactly. We could spend some time decoding the abilities, and create a “dictionary” of different abilities for each Pokémon, but perhaps a better measure may be to simply look at the number of abilities that each Pokémon has:
abilities <- strsplit(as.character(pokedat[["abilities"]]), ", ")
abilities <- sapply(abilities, FUN = function(x) gsub("\\[|\\'|\\]", "", x))
names(abilities) <- rownames(pokedat)
pokedat[["number_abilities"]] <- sapply(abilities, FUN = length)
table(pokedat[["number_abilities"]])##
## 1 2 3 4 6
## 109 245 427 7 13So the majority of Pokémon have only 1, 2 or 3 abilities, with only a small number of Pokémon have more than 3 abilities, and around half having exactly 3.
I want to now look only at the variables that might theoretically be descriptive of the Pokémon in some kind of model. So we can remove the individual abilties (although the number of abiltities will likely be of interest), the names and Pokedex number, and the classification which seems to be fairly ambiguous. We also need to ensure that we use the dummy variables for the variables encoded as factors.
5 Normalization
Prior to doing this, I want to look at a few different ways to normalize all of the variables to ensure that they all have values that are comparable. Some algorithms are more sensitive to normalization than others, and it becomes quite obvious why this may be something to consider here when you consider that whilst the stats value attack lies between 5 and 185, the experience_growth value ranges between 600,000 and 1,640,000. That’s a >10,000-fold increase. This variable will completely dominate the calculations for certain machine-learning algorithms like K-Nearest Neighbours (KNN) and Support Vector Machines (SVM) where the distance between data points is important. SO let’s look at how we might want to normalize these data prior to analysis.
5.1 Min-Max Normalization
There are a few different ways to do this. One way is to standardize the data, so that we bring them all into a common scale of \([0,1]\), but we maintain the distribution for each specific variable. So if one variable has a very skewed distriburtion, this will be maintained. A simple way to do this is to use the min-max scaling approach, where you subtract the lowest value (so that the minimum value is always zero) and then divide by the range of the data so that the data are spread in the range \([0,1]\):
\[x' = \frac{x - x_{min}}{x_{max} - x_{min}}\]
Let’s compare the standardized and non-standardized attack values:
attack_std <- (pokedat[["attack"]] - min(pokedat[["attack"]]))/(max(pokedat[["attack"]]) - min(pokedat[["attack"]]))
data.frame(Raw = pokedat[["attack"]],
Standardized = attack_std) %>%
tidyr::gather("class", "attack", Raw, Standardized) %>%
mutate(class = factor(class, levels = c("Raw", "Standardized"))) %>%
ggplot(aes(x = attack, fill = class)) +
geom_density(alpha = 0.2) +
facet_wrap(. ~ class, scales = "free") +
xlab("Attack Strength") + ylab("Density") +
theme_bw() +
theme(legend.position = "none",
axis.title = element_text(size = 24, face = "bold"),
axis.text = element_text(size = 18),
legend.title = element_text(size = 24, face = "bold"),
legend.text = element_text(size = 20),
strip.text = element_text(size = 24, face = "bold")
)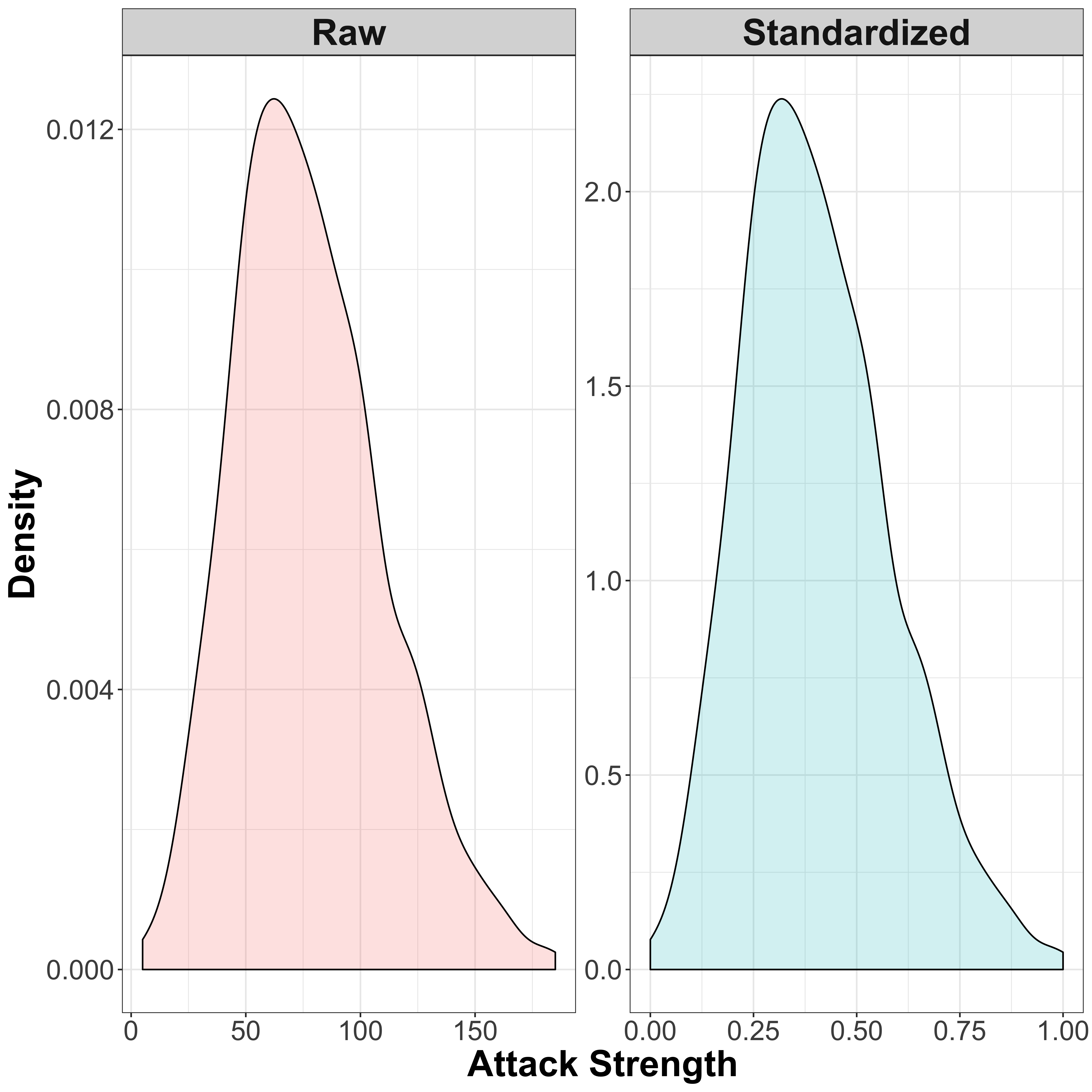
So as you can see here, the distribution of the attack scores remains the same, but the scales over which the distribution is spread are different.
5.2 Z-Score Normalization
However, sometimes it is preferable to instead that every feature has a standard distribution that can be easily described to make them more comparable. In this case, you can normalize the data so that the distribution of all features is shifted towards that of a normal (Gaussian) distribution. This is a typical “bell-shaped” curve, which can be exclusively described by the mean and the standard deviation. An example where I use this approach regularly is in gene-expression analysis, where we normalize the data such that the levels of expression of each gene is represented by a normal distribution, so that we can test for samples where the expression is significantly outside of the confines of this distribution. We can then look at all of the genes that seem to show significantly different expression than we would expect using hypothesis testing approaches, and look for common functions of these genes through the use of network analysis, gene ontology analysis and other downstream analyses.
A simple normalization approach is the z-score normalization, which will transform the data so that the distribution has a mean of 0 and a standard deviation of 1. The transformation is as follows:
\[x' = \frac{x - \mu}{\sigma}\]
So we simply subtract the mean \(\mu\) (to center the data), and divide by the standard deviation \(\sigma\). Let’s again visualise this by comparing the raw and normalized data:
attack_norm <- (pokedat[["attack"]] - mean(pokedat[["attack"]]))/sd(pokedat[["attack"]])
data.frame(Raw = pokedat[["attack"]],
Normalized = attack_norm) %>%
tidyr::gather("class", "attack", Raw, Normalized) %>%
mutate(class = factor(class, levels = c("Raw", "Normalized"))) %>%
ggplot(aes(x = attack, fill = class)) +
geom_density(alpha = 0.2) +
facet_wrap(. ~ class, scales = "free") +
xlab("Attack Strength") + ylab("Density") +
theme_bw() +
theme(legend.position = "none",
axis.title = element_text(size = 24, face = "bold"),
axis.text = element_text(size = 18),
legend.title = element_text(size = 24, face = "bold"),
legend.text = element_text(size = 20),
strip.text = element_text(size = 24, face = "bold")
)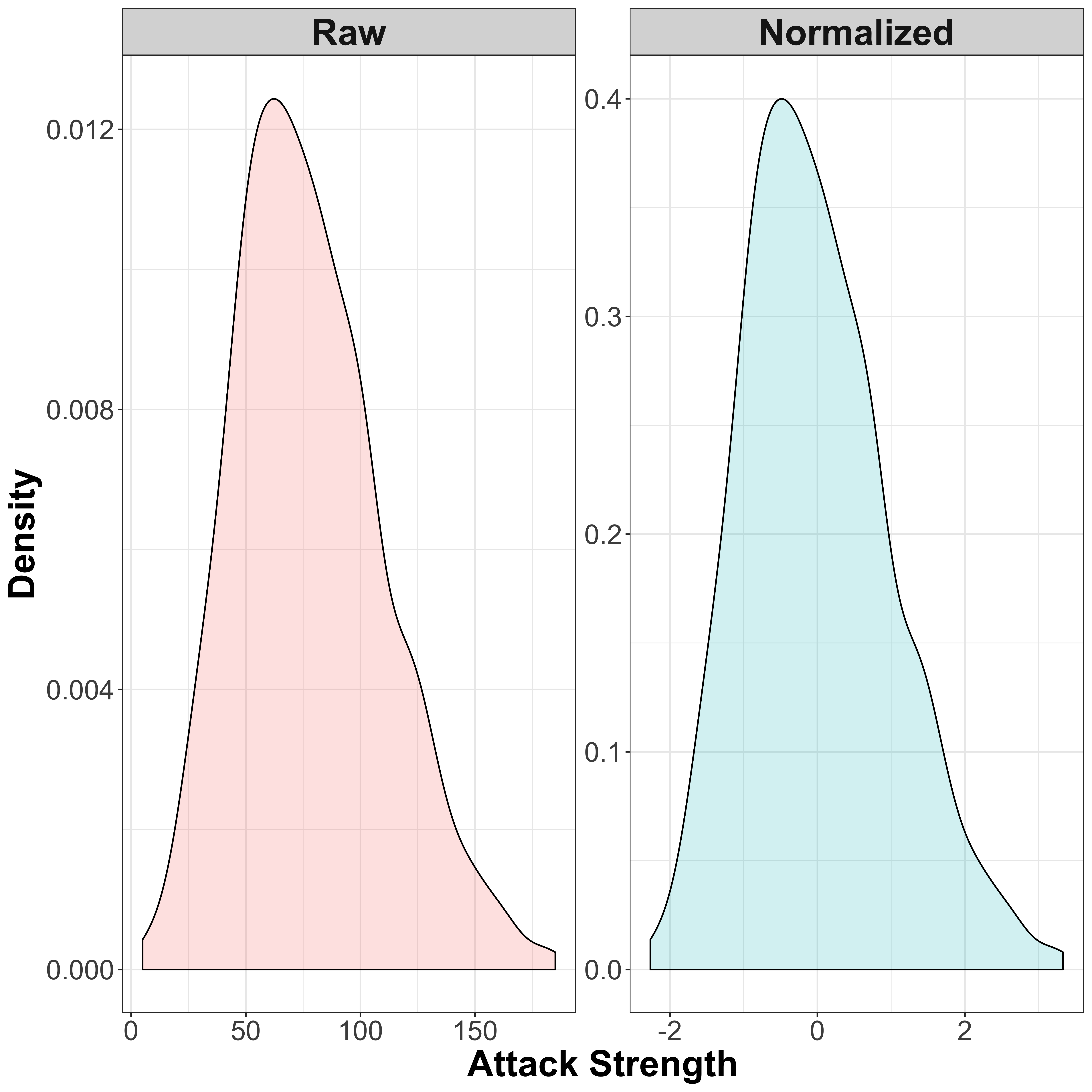
So the normalized data now has a mean of 0, with the majority of values lying between -2 and 2. Note that since this is a fairly simple normalization technique, the distribution itself is not really changed, but there are other methods such as quantile normalization which can reshape the data to a Gaussian curve, or indeed any other dstribution as required.
5.3 Choosing a Normalization Method
The choice of which method to use will largely depend on what you are trying to do. The min-max scaling method is a common method used in machine learning, but does not handle outliers very well – a sample with an extreme value in the raw data will still have an extreme value in the scaled data, resulting in bunching up of the remaining data since it is all bounded within the range \([0,1]\). The Z-score normalization is better at dealing with outliers as they will appear far away from the mean value of 0, but the range of data is no longer bounded meaning that different variables will now have different ranges. Other normalization processes may make your data more homogenous, but at the cost of potentially losing aspects of the data that may be useful.
Many machine learning algorithms use some kind of distance measure, in order to look for similarity between different items. This can be a simple Euclidean distance, which is a k-dimensional measure of “as the crow flies”. If the scales are very different between your variables, then this will cause a significant issue.
For the following analyses, I will use Z-score normalization, since I know that there are a few extreme outliers in these data.
6 Looking for Patterns
6.1 Correlation of Variables
One thing that it is worth doing before heading down a route of data modelling is to look at the correlation structure between the variables in the data set. If there are highly correlated variables (for instance one might imagine height and weight to be highly correlated), then both will offer the same information to the model – adding both will give no additional predictive power than adding only one. There is then a danger of over-fitting the data, which can happen if you create a model so complicated that, whilst it may fit the training data very well, it is so complex as to no longer be applicable to external data sets making it essentially useful. An extreme example is if we create a model where we have one variable for each sample, that is equal to 1 for that specific sample, and 0 for every other sample. This would fit the data perfectly, but would be of absolutely no use for any other data. In addition, we can risk biasing the data by including multiple variables that essentially encode the same information.
So we can calculate a pairwise correlation matrix, which will give us a measure of similarity between each pair of variables by comparing the two vectors of values for the 801 Pokémon. There are multiple measures of correlation that can be used. The standard is the Pearson Correlation, which is a measure of the linearity of the relationship between two values. A value of 1 represents an entirely linear monotonic relationship (as one value increases, so does the other, but with every unit increase in one variable matching a unit increase in the other in a linear way), a value of 0 represents no linearity between the values (no clear relationship between the two), and a value of -1 represents an inverse monotonic linear relationship (anti-correlated).
For this analysis, I will be using the Spearman Correlation coefficient. Instead of using the values themselves, this method first ranks the data, and then looks at the correlation. The idea here is that the unit difference between each successive value is kept constant, meaning that outliers do not have a big impact. This is therefore independent of the distribution of the data, and is therefore a non-parametric method. Since we identified some outliers with some of these variables, this method will remove the effect that these might have.
We can represent these values by using a heatmap, which is a way of representing 3-dimensional data. The value of the correlation, rather than being represented on an axis as a value, will be represented by a colour. Values of the SPearman correlation closer to 1 will appear more red, whilst those closer to -1 will appear more blue. Those closer to 0 will appear white.
In addition, I will apply a hierarchical clustering method to ensure that the variables most similar to one another are located close to one another on the figure. Pairwise distances are calculated by looking at the Euclidean distance, and similar variables are clustered together, allowing us to pick out by eye those most similar to one another.
As mentioned earlier, we first want to ensure that we are looking at numerical values, or at least numerical representations of factors.
pokedat_vals <- pokedat[, !names(pokedat) %in% c("abilities", "classfication", "japanese_name", "name", "pokedex_number")]
pokedat_vals[["type1"]] <- as.numeric(pokedat_vals[["type1"]])
pokedat_vals[["type2"]] <- as.numeric(pokedat_vals[["type2"]])
pokedat_vals[["generation"]] <- as.numeric(pokedat_vals[["generation"]])
pokedat_vals[["is_legendary"]] <- as.numeric(pokedat_vals[["is_legendary"]])This will give us a purely numeric data set for use in numeric calculations. Finally we will normalize the data using Z-score normalization:
pokedat_norm <- scale(pokedat_vals, center = TRUE, scale = TRUE)Finally let’s take a look at the correlation plot:
library("pheatmap")
pokecor_var <- cor(pokedat_norm, method = "spearman")
colors <- colorRampPalette(c('dark blue','white','dark red'))(255)#colorRampPalette( rev(brewer.pal(9, "Blues")) )(255)
pheatmap(pokecor_var,
clustering_method = "complete",
show_colnames = FALSE,
show_rownames = TRUE,
col=colors,
fontsize_row = 24) 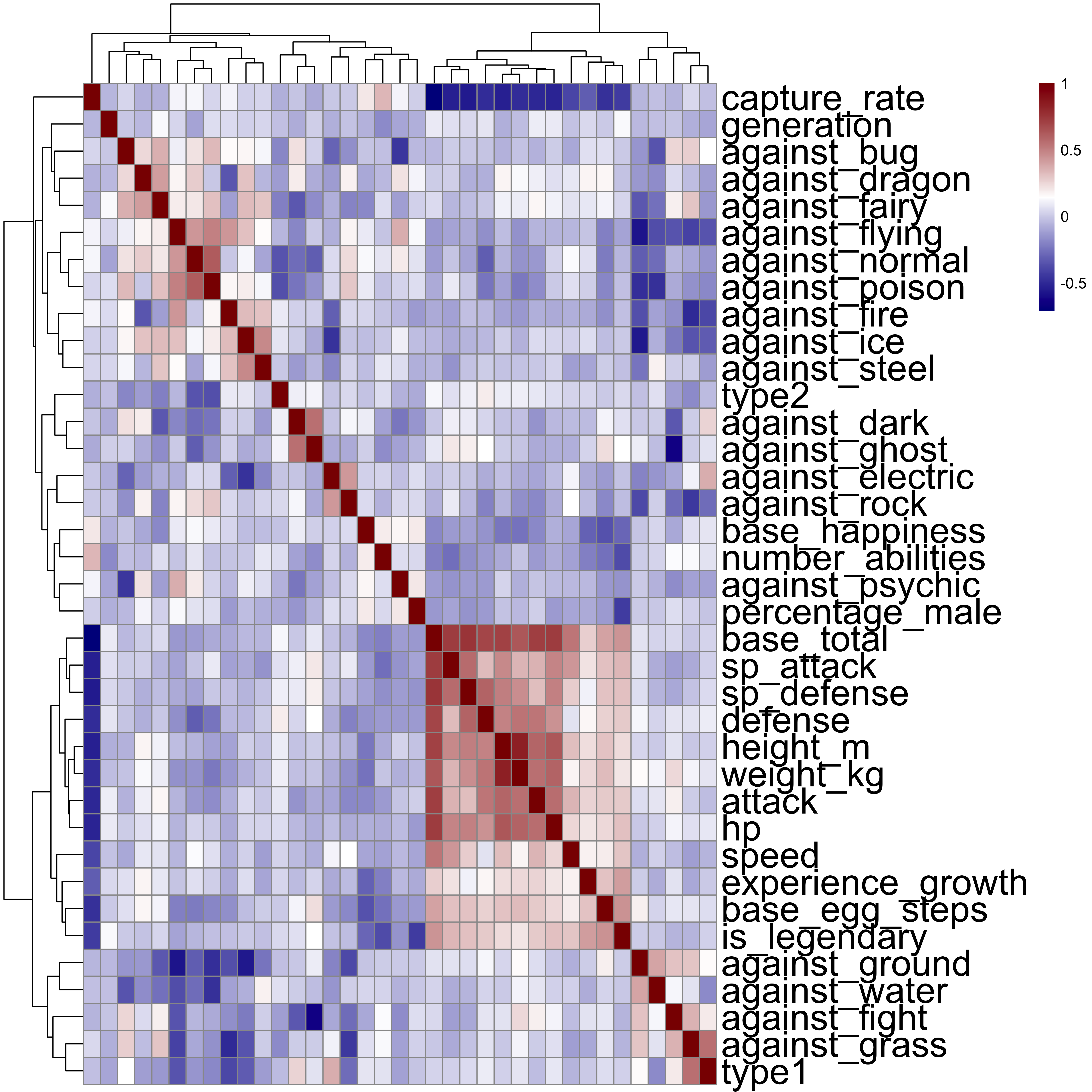
We can see a few clear cases of correlated variables here, especially between a few of the values giving attack strength against certain Pokémon types. For instance, attack against ghost- and dark-type Pokémon are very similar (which makes sense), as are attacks against electric- and rock-type Pokémon (makes less sense). The clearest aspect of the figure is a block of high positive correlations between a number of variables associated with the Pokémon’s vital statistics. So the most similar variables are those like speed, defence strength, attack strength, height, weight, health points, experience growth, etc. This makes a lot of sense, with bigger Pokémon having better attack and defence, more health points, etc. We also see that these variables are very highly anti-correlated with the capture-rate, which again makes sense – the better Pokémon are harder to catch. However, none of these correlations seem significantly high to require the remobval of any variables prior to analysis.
6.2 Height vs Weight
Let’s take a look at the height vs the weight. We can also include a few additional variables to see how the Pokémon strength and defence affect the relationship. I am going to scale both the x-and y-axes by using a \(log_{10}\) transformation to avoid much larger Pokémon drowing out the smaller ones:
ggplot(aes(x = height_m, y = weight_kg, color = attack, size = defense), data = pokedat) +
geom_point(alpha = 0.2) +
scale_color_gradient2(name = "Attack", midpoint = mean(pokedat[["attack"]]), low = "blue", mid = "white", high = "red") +
scale_size_continuous(name = "Defence", range = c(1, 10)) +
xlab("Height (m)") + ylab("Weight (Kg)") +
scale_x_log10() +
scale_y_log10() +
#theme_bw() +
theme(axis.title = element_text(size = 24, face = "bold"),
axis.text = element_text(size = 18),
legend.title = element_text(size = 24, face = "bold"),
legend.text = element_text(size = 20),
strip.text = element_text(size = 24, face = "bold")
)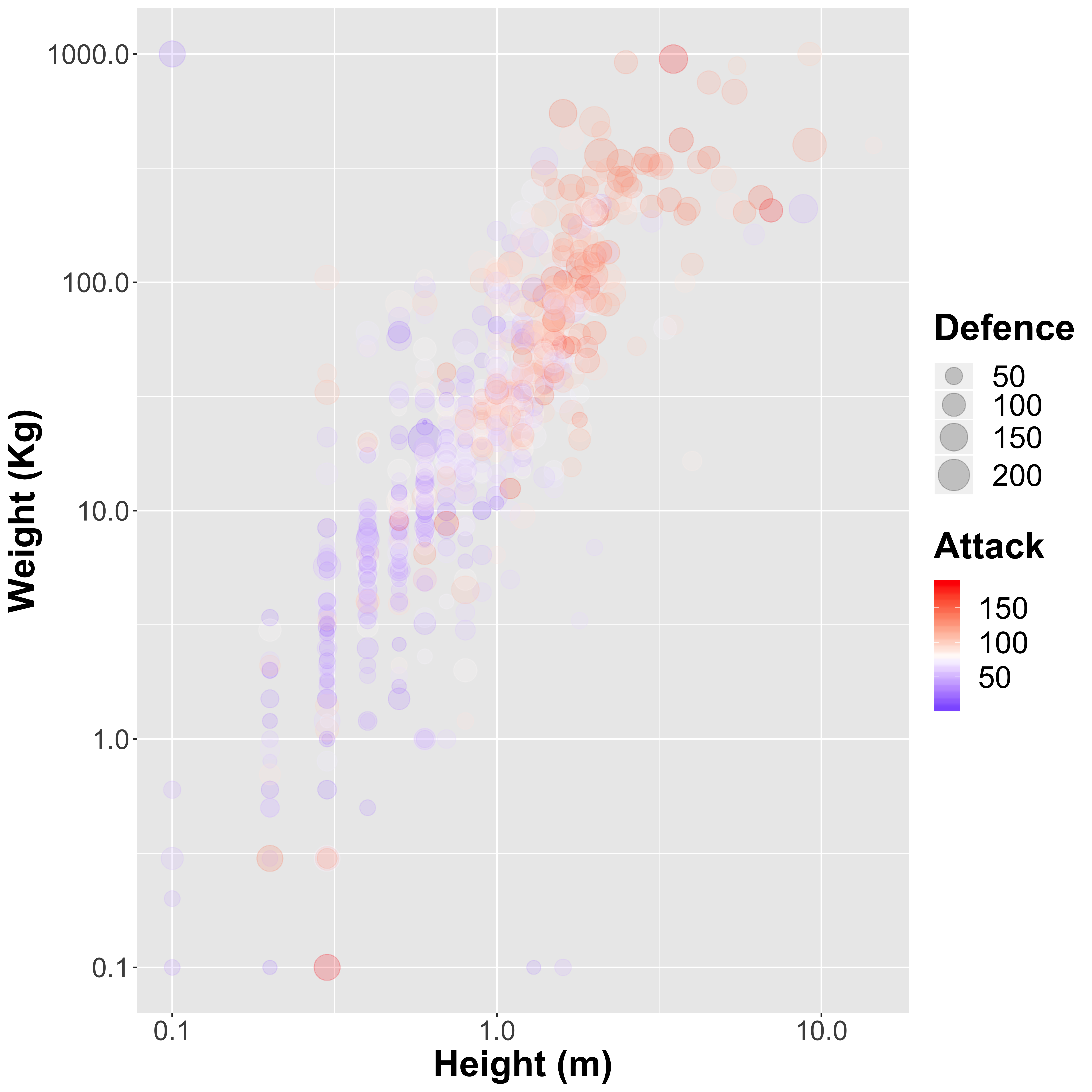
So there is a clear relationship, and in general taller Pokémon (such as Walor, the largest of the Pokémon) also weigh more as we might expect:

Walord, the largest Pokemon
We also see that in general the attack strength of the larger Pokémon is higher than the smaller ones, although there are definitely some outliers, such as Cosmeom, a legendary Pokémon only 10 cm tall that weighs nearly 1,000 kg!

Cosmoem, the smallest Pokemon
6.3 Correlation between Pokémon
pokecor_sample <- cor(t(pokedat_norm), method = "spearman")
colors <- colorRampPalette(c('dark blue','white','dark red'))(255)
pheatmap(pokecor_sample,
clustering_method = "complete",
show_colnames = FALSE,
show_rownames = FALSE,
annotation = pokedat[, c("generation", "type1", "type2", "is_legendary")],
col=colors) 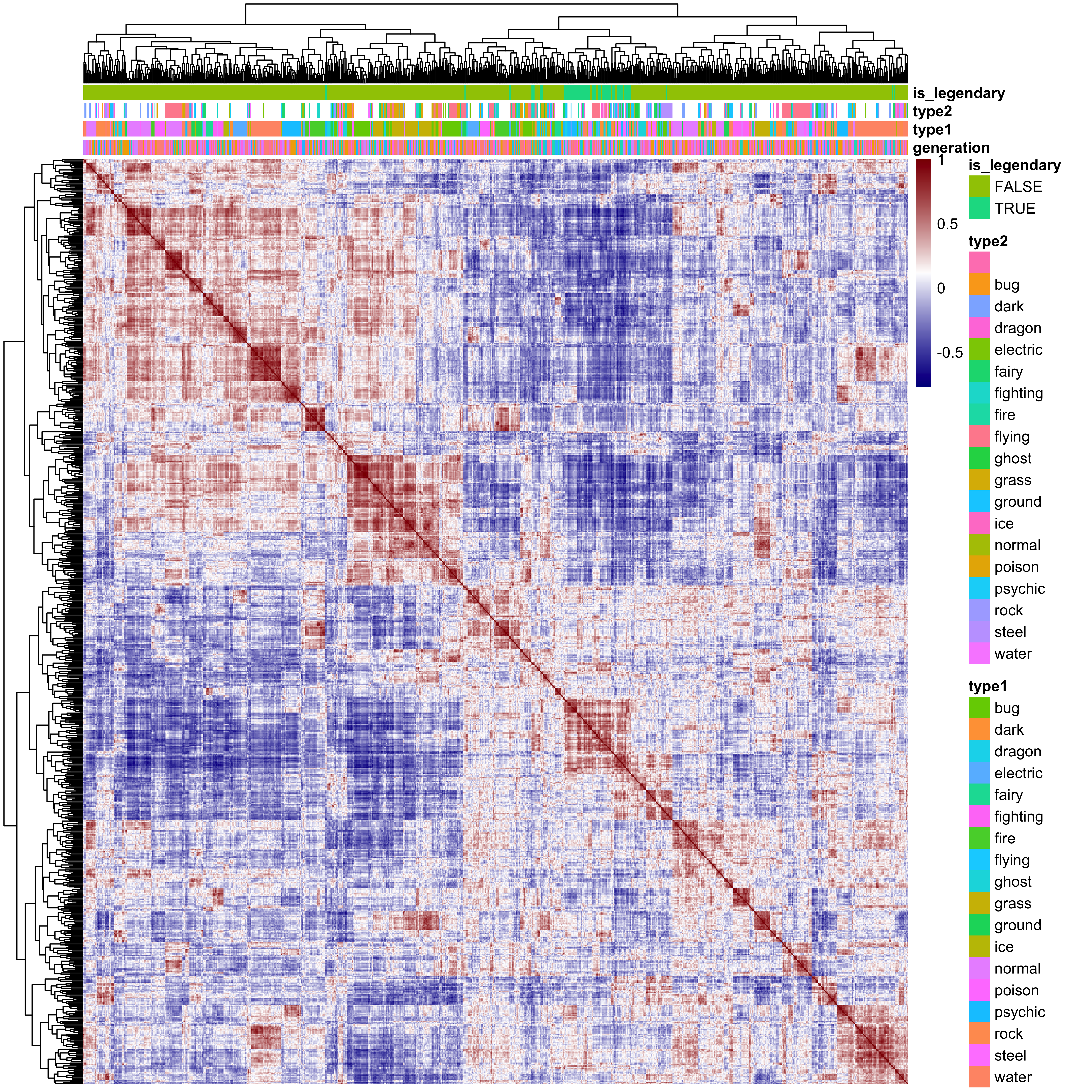
So here we see the correlation structure between the 801 Pokémon, and it very clearly shows similarities between groups of Pokémon. The red boxes that we see down the diagonal represent highly similar groups, and at the top I have annotated the factor variables generation, type1, type2 and is_legendary. Almost all of the legendary Pokémon cluster together, suggesting that these are all similar to one another across these variables. Similarly there are a number of Pokémon types that clearly cluster together, such as rock type and dark type Pokémon. Interestingly the Generation number seems to be unrelated to Pokémon similarity.
6.4 Principal Component Analysis
A good way to explore data such as these to look for underlying trends in the data is to use a dimensional-reduction algorithm to reduce these high-dimensional data down into asmaller number of easy to digest chunks. Principal component analysis (PCA) is one such approach, and can be used to look for the largest sources of variation within a high dimensional data set. For a data set with n variables, we can think of these data existing in an n-dimensional space. PCA is a mathematical trick that rotates these axes in n-dimensional space so that the x-axis of the rotation explains the largest possible amount of variation in the data, the y-axis then explains the next largest possible amount of variation, the z-axis the next largest amount, etc. In many cases, a very large amount of the total variation in the original n-dimensional data set can be captured by only a small number of so-called principal components. This can be used to look for underlying trends in the data. So let’s have a look at how this looks:
pc <- prcomp(pokedat_vals, scale. = TRUE)
pc_plot <- as.data.frame(pc[["x"]])
pc_plot <- cbind(pc_plot, pokedat[rownames(pc_plot), c("generation", "type1", "type2", "is_legendary")])
explained_variance <- 100*((pc[["sdev"]])^2 / sum(pc[["sdev"]]^2))
screeplot(pc, type = "line", main = "Principal Component Loadings")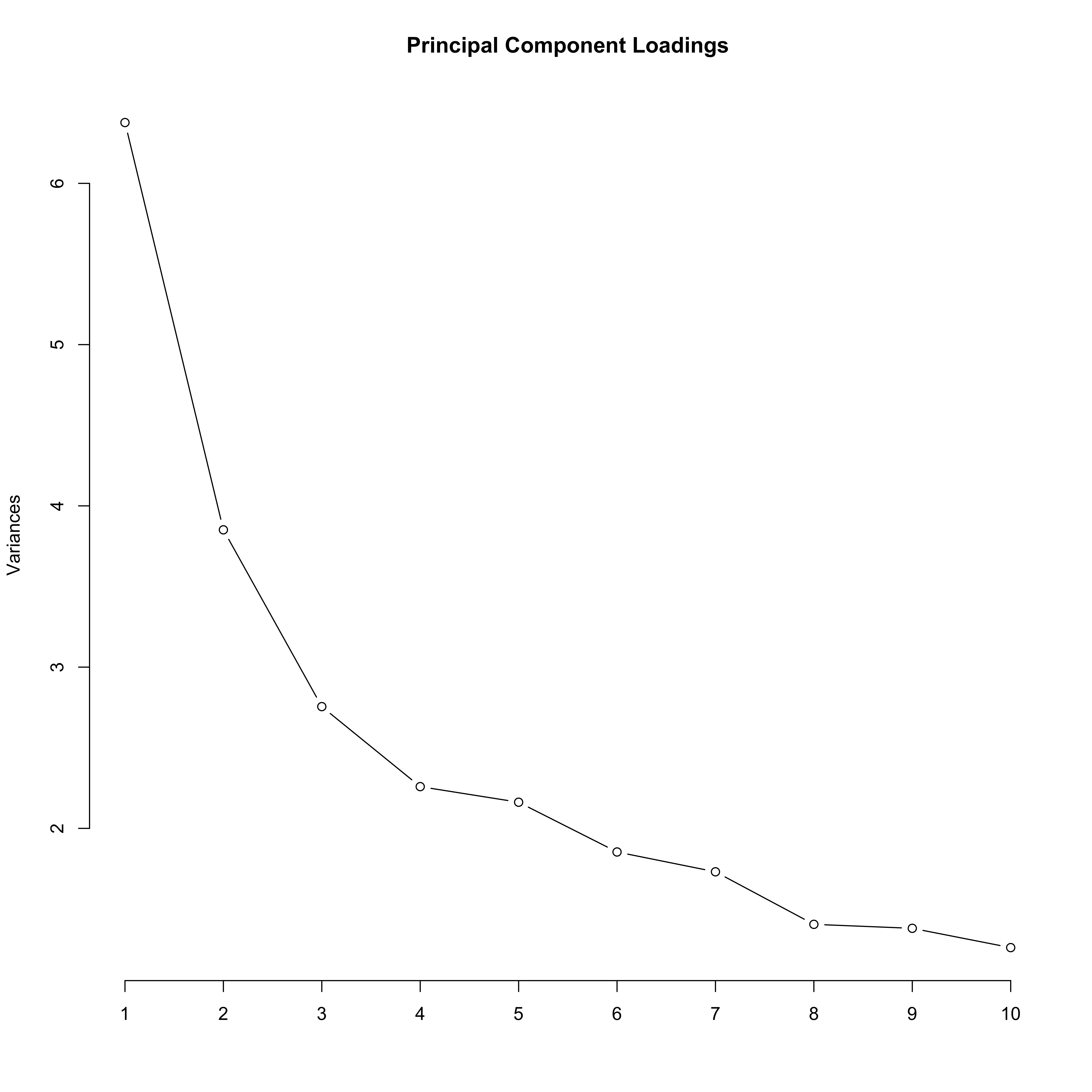
In this plot, we see that PC1 and PC2 explain a lot of variance compared to the other PCs, but the drop off is not complete at this point. In a lot of data sets, the first few PCs explain the vast majority of the variance, and so this plot drops off considerably to a flat line by PC3 or PC4. Let’s take a look at how discriminatory these PCs are to these data:
ggplot(aes(x = PC1, y = PC2, shape = is_legendary, color = type1), data = pc_plot) +
geom_point(size = 5, alpha = 0.7) +
xlab(sprintf("PC%d (%.2f%%)", 1, explained_variance[1])) +
ylab(sprintf("PC%d (%.2f%%)", 2, explained_variance[2])) +
theme(axis.title = element_text(size = 14, face = "bold"),
axis.text = element_text(size = 12),
legend.title = element_text(size = 18, face = "bold"),
legend.text = element_text(size = 14))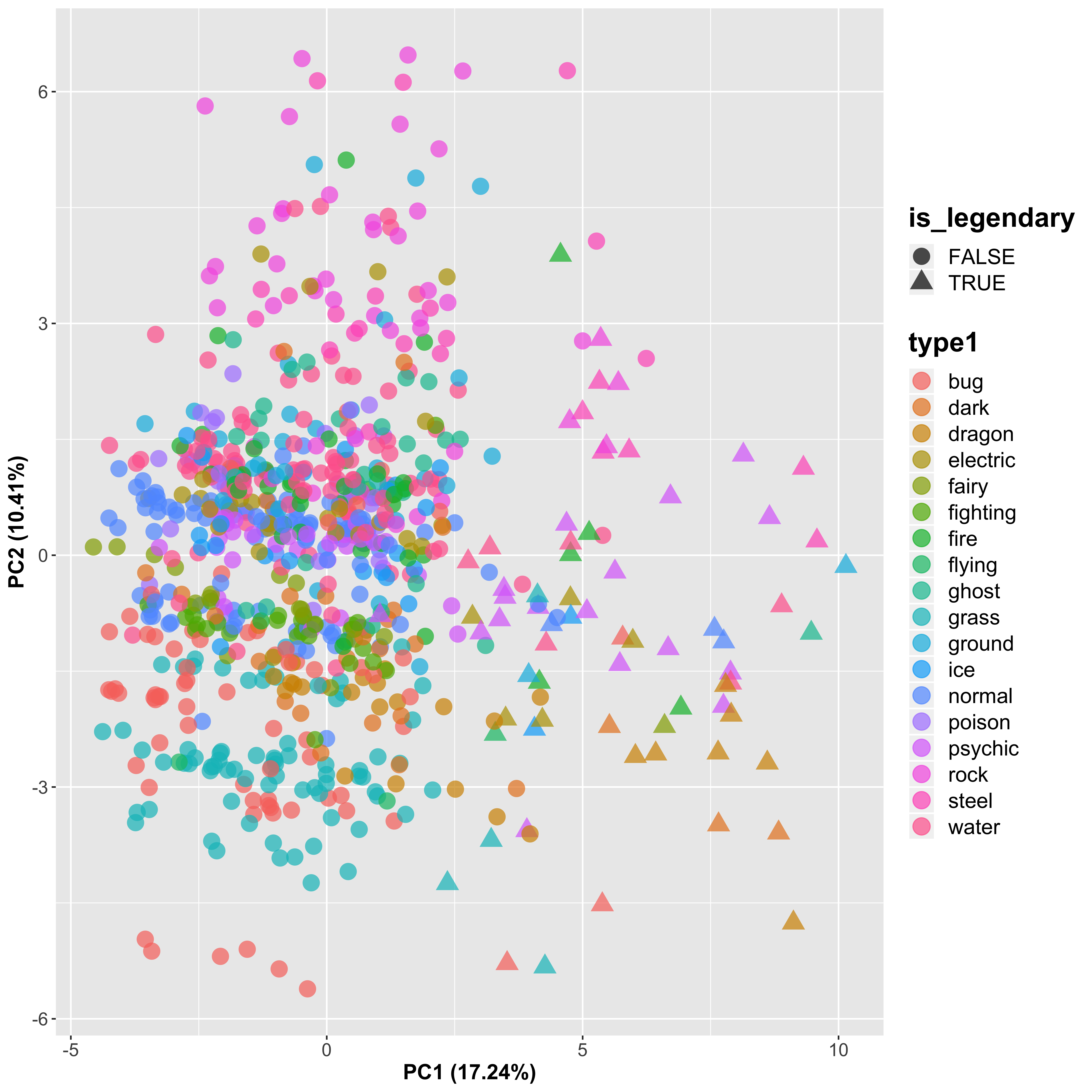
We can see that this PCA approach clearly discriminates the legendary Pokémon (triangles) from the other Pokémon (circles) in PC1, which is the new axis that explains the most variance in the data (although note that this is still only 17.2%, so not a huge amount really). There is some separation seen between the different Pokémon groups, which seems to represent the second most significant source of variation, accounting for another 10.4%. Let’s look at PC3 as well to see if this is able to discriminate the samples further:
ggplot(aes(x = PC2, y = PC3, shape = is_legendary, color = type1), data = pc_plot) +
geom_point(size = 5, alpha = 0.7) +
xlab(sprintf("PC%d (%.2f%%)", 2, explained_variance[2])) +
ylab(sprintf("PC%d (%.2f%%)", 3, explained_variance[3])) +
theme(axis.title = element_text(size = 14, face = "bold"),
axis.text = element_text(size = 12),
legend.title = element_text(size = 18, face = "bold"),
legend.text = element_text(size = 14))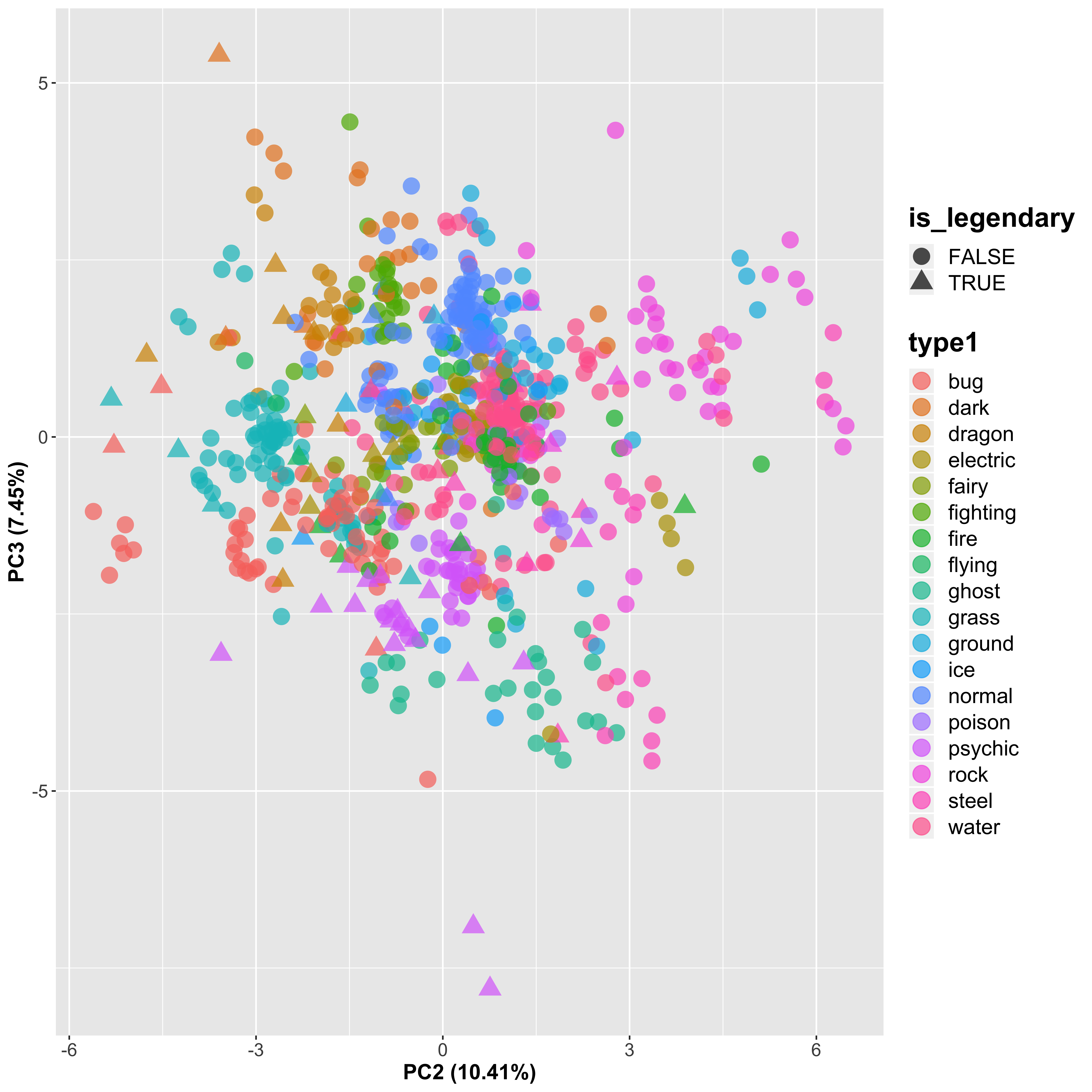
By looking at the 2nd and 3rd PCs, we do see a slight separation between the Pokémon types, but it is not strong.
6.5 Correlation-Based Recommendation
As a little aside, I want to see whether it is possible to recommend similar Pokémon to any Pokémon that you might suggest. For instance, my daughter’s absolute favourite is Eevee (a cuddly fox-like Pokémon):

Eeevee
So let’s see whether there are any other Pokémon that are similar to Eevee, based on a simple correlation match. To do this, I will calculate the Spearman correlation coefficient between Eevee and every other Pokémon, and see which the most similar are:
eevee <- as.numeric(pokedat_vals["Eevee", ])
eevee_cor <- apply(pokedat_vals, MAR = 1, FUN = function (x) cor(x, eevee, method = "spearman"))
head(sort(eevee_cor, decreasing = TRUE), 10)## Eevee Aipom Sentret Teddiursa Patrat Zigzagoon Rattata
## 1.0000000 0.9781018 0.9728923 0.9695460 0.9693680 0.9690263 0.9689643
## Meowth Raticate Bidoof
## 0.9687552 0.9676089 0.9669312So here are a few of the most similar Pokémon:

Aipom

Sentret

Teddiursa

Patrat
Well they all look kind of cuddly like Eevee, except for the really creepy evil beaver Patrat at the end!
However, what would be even more efficient (maybe not in this case, but in the case of a much higher-dimensional data set like a gene-expression data set of 30,000 genes) is to use the reduced dataset after using PCA. The first 10 PCs explained around two thirds of the variance on the data, so by using these 10 values rather than the 37 values originally, we reduce the computations with a relatively small loss of data. Let’s see what the outputs are in this case:
pc_df_sub <- as.data.frame(pc[["x"]])[, 1:10]
eevee <- as.numeric(pc_df_sub["Eevee", ])
eevee_cor_pca <- apply(pc_df_sub, MAR = 1, FUN = function (x) cor(x, eevee, method = "spearman"))
head(sort(eevee_cor_pca, decreasing = TRUE), 10)## Eevee Spinda Delcatty Watchog Aipom Furret Smeargle
## 1.0000000 0.9636364 0.9515152 0.9515152 0.9393939 0.9272727 0.9030303
## Herdier Vanillish Meowth
## 0.9030303 0.9030303 0.8909091
Spinda

Delcatty

Watchog

Furret
Similarly cute, but with another creepy one! After checking with the experiment subject (my daughter), it seems that the best hits are definitely Watchog and Furret, so this seems to cope well at picking out similarly cuddly looking Pokémon.
Obviously here we are simply looking for Pokémon with similar characteristics. This is not as in-depth as a collaboritive filtering method where we have some subjective ranking of items to help us to determine the best Pokémon to match somebody’s needs. However, by using the reduced PCA data set we are able to find very close matches using only a reduced subset of the data.
7 Predicting Legendary Pokémon
Based on our previous analyses, we see that there is a clear discrimination between normal and Legendary Pokémon. These are incredibly rare, and very powerful Pokémon in the game. So is it possible to identify a Legendary Pokémon based on the variables available from this database? And if so, which variables are the most important?
To do predictive modelling, we need to first split our data up into a training data set to use to train the model, and then a validation data set to use to confirm the accuracy of the predictions that this model makes. There are more robust ways to do this, such as cross-validation and bootstrapping, which allow you to assess the accuracy of the model. Cross validation can be applied simply by using the caret package in R.
We will also split the data randomly into two data sets – one containing 80% of the Pokémon for training the model, and one containing 20% of the Pokémon for validation purposes. For the following model fitting approaches, we do not need to have the categorical data converted into numbers as we did for the correlation analysis, as the factors will be treated correctly automatically We do however still need to ignore the non-informative variables. In addition, I am going to remove the “against_” columns to avoid overfitting of the data. So let’s generate our two data sets:
library("caret")
set.seed(0)
split_index <- createDataPartition(y = pokedat[["is_legendary"]], p = 0.8, list = FALSE)
rm_index <- which(names(pokedat) %in% c("abilities", "classfication", "japanese_name", "name", "pokedex_number"))
rm_index <- c(grep("against", names(pokedat)), rm_index)
training_dat <- pokedat[split_index, -rm_index]
validation_dat <- pokedat[-split_index, -rm_index]So let’s try a few different common methods used for classification purposes.
7.1 Support-Vector Machine
We can then train our SVM model, incorporating a preprocessing step to center and scale the data, and performing 10-fold repeated cross validation which we repeat 3 times:
set.seed(0)
trctrl <- trainControl(method = "repeatedcv", number = 10, repeats = 3)
model_svm <- train(is_legendary ~.,
data = training_dat,
method = "svmLinear",
trControl = trctrl,
preProcess = c("center", "scale"),
tuneLength = 10)
model_svm## Support Vector Machines with Linear Kernel
##
## 641 samples
## 18 predictor
## 2 classes: 'FALSE', 'TRUE'
##
## Pre-processing: centered (56), scaled (56)
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 577, 576, 576, 577, 577, 578, ...
## Resampling results:
##
## Accuracy Kappa
## 0.9802138 0.8782632
##
## Tuning parameter 'C' was held constant at a value of 1So this model is able to predict whether the Pokémon is Legendary based on these 18 predictor variables with 98.02% accuracy (correct predictions). The Kappa value is normalised to account for the fact that we could get pretty good accuracy if we just called everything not Legendary due to the imbalance in the classes.
This accuracy is based on resampling of the training data. How does it cope with the validation data? Let’s take a look at the confusion matrix for the predicted outcomes compared to the true values:
predict_legendary <- predict(model_svm, newdata = validation_dat)
svm_confmat <- confusionMatrix(predict_legendary, validation_dat[["is_legendary"]])
svm_confmat## Confusion Matrix and Statistics
##
## Reference
## Prediction FALSE TRUE
## FALSE 144 1
## TRUE 2 13
##
## Accuracy : 0.9812
## 95% CI : (0.9462, 0.9961)
## No Information Rate : 0.9125
## P-Value [Acc > NIR] : 0.000314
##
## Kappa : 0.8863
##
## Mcnemar's Test P-Value : 1.000000
##
## Sensitivity : 0.9863
## Specificity : 0.9286
## Pos Pred Value : 0.9931
## Neg Pred Value : 0.8667
## Prevalence : 0.9125
## Detection Rate : 0.9000
## Detection Prevalence : 0.9062
## Balanced Accuracy : 0.9574
##
## 'Positive' Class : FALSE
## SO according to these multiple statistics, of the 14 Legendary Pokémon in the validation data, we correctly identified 13 of them, but missed 1. 2 were identified incorrectly. Our ultimate accuracy is 98.12%, which seems to be pretty good. However, it is possible to further tune this model, by adjusting the tuning parameter C, by tweaking the parameters included in the model, and moving from a linear SVM model. However, all told, this is a pretty good result.
7.2 k-Nearest Neighbour
Another classification method is the k-Nearest Neighbour (kNN) algorithm. The idea here is that a record is kept of all of the data in the training data, and a new sample is compared to find the k samples “closest” to it. The classification is then calculated based on some average of the classifications of these nearest neighbours. The method of determining the “nearest” neighbour can be one of a number of different methods, including Euclidean distance as described earlier.
Also, the value of k is very important. Using the caret package in R, we are able to test using multiple different values of k to find the value that optimises the model accuracy. So let’s train our model, again performing 10-fold repeated cross validation which we repeat 3 times:
set.seed(0)
trctrl <- trainControl(method = "repeatedcv", number = 10, repeats = 3)
model_knn <- train(is_legendary ~.,
data = training_dat,
method = "knn",
trControl = trctrl,
preProcess = c("center", "scale"),
tuneLength = 10)
model_knn## k-Nearest Neighbors
##
## 641 samples
## 18 predictor
## 2 classes: 'FALSE', 'TRUE'
##
## Pre-processing: centered (56), scaled (56)
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 577, 576, 576, 577, 577, 578, ...
## Resampling results across tuning parameters:
##
## k Accuracy Kappa
## 5 0.9470304 0.5515501
## 7 0.9444345 0.5158836
## 9 0.9428470 0.4854601
## 11 0.9376461 0.4246775
## 13 0.9350660 0.3903400
## 15 0.9355788 0.3898290
## 17 0.9376542 0.4161790
## 19 0.9376784 0.4063420
## 21 0.9355786 0.3765296
## 23 0.9381750 0.4070014
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was k = 5.We can see that the accuracy is optimised by using k = 5 nearest neighbours, which gives an accuracy of 94.7% – below that of the SVM accuracy. Now let’s test it on the validation data set:
predict_legendary <- predict(model_knn, newdata = validation_dat)
knn_confmat <- confusionMatrix(predict_legendary, validation_dat[["is_legendary"]])
knn_confmat## Confusion Matrix and Statistics
##
## Reference
## Prediction FALSE TRUE
## FALSE 145 4
## TRUE 1 10
##
## Accuracy : 0.9688
## 95% CI : (0.9286, 0.9898)
## No Information Rate : 0.9125
## P-Value [Acc > NIR] : 0.004163
##
## Kappa : 0.7833
##
## Mcnemar's Test P-Value : 0.371093
##
## Sensitivity : 0.9932
## Specificity : 0.7143
## Pos Pred Value : 0.9732
## Neg Pred Value : 0.9091
## Prevalence : 0.9125
## Detection Rate : 0.9062
## Detection Prevalence : 0.9313
## Balanced Accuracy : 0.8537
##
## 'Positive' Class : FALSE
## So we can already see that the results of this model are less positive than the SVM model.
7.3 Logistic Regression
For classification problems with only two groups, linear regression is often a good first option. This is a generalised linear model, where we require a transformation of the response variable to ensure that it fits a continuous scale. In this case, the response variable is the probability of being in the Legendary class, so we need to map this to the simple yes/no outcome of the input training data. The logit function is often used, which is a transformation between a probability p and a real number:
\[logit(p) = log(\frac{p}{1-p})\]
So let’s fit a logistic regression model containing all of our data, again using 3 repeats of 10-fold cross validation, and see what we get back:
set.seed(0)
trctrl <- trainControl(method = "repeatedcv", number = 10, repeats = 3)
model_logreg <- train(is_legendary ~.,
data = training_dat,
method = "glm",
family = "binomial",
trControl = trctrl,
preProcess = c("center", "scale"),
tuneLength = 10)
model_logreg## Generalized Linear Model
##
## 641 samples
## 18 predictor
## 2 classes: 'FALSE', 'TRUE'
##
## Pre-processing: centered (56), scaled (56)
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 577, 576, 576, 577, 577, 578, ...
## Resampling results:
##
## Accuracy Kappa
## 0.9667197 0.802881So we actually get a better accuracy from the cross-validation than for SVM or kNN at 96.67% accuracy. So let’s test it on the validation data set:
predict_legendary <- predict(model_logreg, newdata = validation_dat)
logreg_confmat <- confusionMatrix(predict_legendary, validation_dat[["is_legendary"]])
logreg_confmat## Confusion Matrix and Statistics
##
## Reference
## Prediction FALSE TRUE
## FALSE 141 1
## TRUE 5 13
##
## Accuracy : 0.9625
## 95% CI : (0.9202, 0.9861)
## No Information Rate : 0.9125
## P-Value [Acc > NIR] : 0.01131
##
## Kappa : 0.792
##
## Mcnemar's Test P-Value : 0.22067
##
## Sensitivity : 0.9658
## Specificity : 0.9286
## Pos Pred Value : 0.9930
## Neg Pred Value : 0.7222
## Prevalence : 0.9125
## Detection Rate : 0.8812
## Detection Prevalence : 0.8875
## Balanced Accuracy : 0.9472
##
## 'Positive' Class : FALSE
## The accuracy of this model on the validation data set is 96.25%.
7.4 Random Forest
As a final model, we will look at using a random forest classifier. A random forest is essentially created by creating a number of decision trees and averaging over them all. I will use the same cross-validation scheme as previously, and will allow caret to identify the optimum parameters:
set.seed(0)
trctrl <- trainControl(method = "repeatedcv", number = 10, repeats = 3)
model_rf <- train(is_legendary ~.,
data = training_dat,
method = "rf",
trControl = trctrl,
preProcess = c("center", "scale"),
tuneLength = 10)
model_rf## Random Forest
##
## 641 samples
## 18 predictor
## 2 classes: 'FALSE', 'TRUE'
##
## Pre-processing: centered (56), scaled (56)
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 577, 576, 576, 577, 577, 578, ...
## Resampling results across tuning parameters:
##
## mtry Accuracy Kappa
## 2 0.9911611 0.9396362
## 8 0.9984292 0.9905178
## 14 0.9984292 0.9905178
## 20 0.9984292 0.9905178
## 26 0.9984292 0.9905178
## 32 0.9984292 0.9905178
## 38 0.9984292 0.9905178
## 44 0.9984292 0.9905178
## 50 0.9984292 0.9905178
## 56 0.9984292 0.9905178
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was mtry = 8.This approach identified an accuracy of 99.84% (with a normalised kappa value of 99.05%) with an mtry value of 8. This is incredibly good, and is the best outcome so far. However, it is worth noting that this approach is significantly slower than the others. Let’s check against our validation data set:
predict_legendary <- predict(model_rf, newdata = validation_dat)
confusionMatrix(predict_legendary, validation_dat[["is_legendary"]])## Confusion Matrix and Statistics
##
## Reference
## Prediction FALSE TRUE
## FALSE 145 1
## TRUE 1 13
##
## Accuracy : 0.9875
## 95% CI : (0.9556, 0.9985)
## No Information Rate : 0.9125
## P-Value [Acc > NIR] : 0.00005782
##
## Kappa : 0.9217
##
## Mcnemar's Test P-Value : 1
##
## Sensitivity : 0.9932
## Specificity : 0.9286
## Pos Pred Value : 0.9932
## Neg Pred Value : 0.9286
## Prevalence : 0.9125
## Detection Rate : 0.9062
## Detection Prevalence : 0.9125
## Balanced Accuracy : 0.9609
##
## 'Positive' Class : FALSE
## So whilst the training accuracy is nearly 100%, here we see slightly lower accuracy on the test data set. It is still pretty good going, but could still be improved.
8 Conclusion
We have managed to explore these data in a number of different ways and have identified some interesting themes and patterns. However, there is a lot of additional work that can be done. Correlation-based recommendation seems to work to identify similar Pokémon, at least in the small number of cases that I looked at. My wife showed me this toy that can guess any Pokémon that you think of, which probably uses a similar approach. I’m in the wrong business…
It is worth noting that here I have concentrated predominantly on the accuracy of the model, but in general this is not the only metric that we should be interested in. As mentioned previously, given how many more non-Legendary Pokémon there are, we would get a pretty good accuracy if we just assumed that none of the test samples were Legendary. Sensitivity and Specificity for instance are useful to look at, which define the proportion of samples called correctly as Legendary (True Positives) and the proportion of those called correctly as not Legendary (Truse Negatives). Often, if we think of the opposite of these, False Negatives are more of an issue than False Positives – e.g. for disease prediction we would probably prefer not to miss any potential cases.
Also, whilst it was interesting to play with some of the most commonly used machine learning methods, I have spent no real time tuning the model parameters. The variables themselves used in the data set could be tweaked to identify those variables most associated with the response variable. Given that these are incredibly rare and powerful Pokémon, we will inevitably find that the fighting based variables like attack and defence are highly discriminative, but also those such as the capture rate and experience growth associated. In addition, we have looked only at additive models here and have not considered interaction terms. We can also spend time fine-tuning the parameters of the models themselves to improve the accuracy further.
However, despite this, we got some very good results from the default model parameters for several commonly used methods. kNN, SVM, logistic regression and random forests gave very similar results, but with SVM and random forest giving the best predictive outcomes.
Ultimately, the key to developing any machine learning algorithm is to trial multiple different approaches and tune the parameters for the specific data in question. Also, a machine learning algorithm is only as good as the data that it is trained on, so feeding in more good quality cleaned data will help the model to learn. Ultimately, machine learning is aimed at developing a model that is able to predict something from new data, so it needs to be as generalised as possible.
So hopefully when I come across a new Pokémon not currently found in my Pokedex, I can easily check whether it is Legendary by asking it a few questions about its vital statistics. Very useful.
Gotta catch ’em all!
9 Session Info
sessionInfo()## R version 3.6.1 (2019-07-05)
## Platform: x86_64-apple-darwin15.6.0 (64-bit)
## Running under: macOS Sierra 10.12.6
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_GB.UTF-8/en_GB.UTF-8/en_GB.UTF-8/C/en_GB.UTF-8/en_GB.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] caret_6.0-84 lattice_0.20-38 pheatmap_1.0.12
## [4] RColorBrewer_1.1-2 ggrepel_0.8.1 dplyr_0.8.3
## [7] ggplot2_3.2.1
##
## loaded via a namespace (and not attached):
## [1] Rcpp_1.0.2 lubridate_1.7.4 tidyr_1.0.0
## [4] class_7.3-15 assertthat_0.2.1 zeallot_0.1.0
## [7] digest_0.6.22 ipred_0.9-9 foreach_1.4.7
## [10] R6_2.4.0 plyr_1.8.4 backports_1.1.5
## [13] stats4_3.6.1 evaluate_0.14 e1071_1.7-2
## [16] blogdown_0.16 pillar_1.4.2 rlang_0.4.1
## [19] lazyeval_0.2.2 data.table_1.12.6 kernlab_0.9-27
## [22] rpart_4.1-15 Matrix_1.2-17 rmarkdown_1.16
## [25] labeling_0.3 splines_3.6.1 gower_0.2.1
## [28] stringr_1.4.0 munsell_0.5.0 compiler_3.6.1
## [31] xfun_0.10 pkgconfig_2.0.3 htmltools_0.4.0
## [34] nnet_7.3-12 tidyselect_0.2.5 tibble_2.1.3
## [37] prodlim_2018.04.18 bookdown_0.14 codetools_0.2-16
## [40] randomForest_4.6-14 crayon_1.3.4 withr_2.1.2
## [43] MASS_7.3-51.4 recipes_0.1.7 ModelMetrics_1.2.2
## [46] grid_3.6.1 nlme_3.1-141 gtable_0.3.0
## [49] lifecycle_0.1.0 magrittr_1.5 scales_1.0.0
## [52] stringi_1.4.3 reshape2_1.4.3 timeDate_3043.102
## [55] ellipsis_0.3.0 generics_0.0.2 vctrs_0.2.0
## [58] lava_1.6.6 iterators_1.0.12 tools_3.6.1
## [61] glue_1.3.1 purrr_0.3.3 survival_2.44-1.1
## [64] yaml_2.2.0 colorspace_1.4-1 knitr_1.25Sam Robson
Lead Bioinformatician at the Centre for Enzyme Innovation
Lead Bioinformatician at the Centre for Enzyme Innovation